フォントの構造などは上記ページに詳細が掲載されていますので、そちらを参考にしてください。
で、試しにフォントにアクセスするソースを作成してみました。
考えながら超適当に作ったので汚いソースですが、時間があれば整理します。
fontx_ana.cpp
MinGW版gcc(on Windows)で動作確認しています。(実行ファイル)
このプログラムは、最低8x8ドット、最大48x48ドット、横幅が8の倍数になるフォントのみ
対応しています。
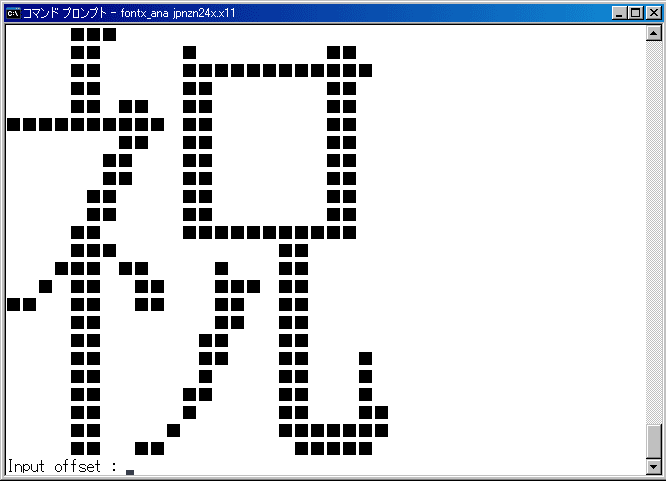
祝!動きました。
フォント形式は多種存在しますが、FONTX形式は入手性の良い部類に入ります。
ここでは、東雲フォントを表示したいと思います。
参考サイト:FONTX Home Page(現在リンク切れ)
これについて調べてみたいと思います。
FONTX2形式は、Windows3.1より前の時代に日本語フォントROMを持たないIBM PC/AT
(またはその互換機)で日本語の表示を行うために作られたソフトウェアで
利用されていたフォント形式をベースに発展してきたものです。
さて、このFONTX形式は、そういった枠を超え、X-Windowなどでも
利用されているようです。
フリーでこの形式のフォントデータを入手することができます。
そこで、組込みマイコンから日本語を表示することを念頭に、まずはFONTX形式とはどんなものかということをスタディし、実際に実装して動作させたいと思います。
まず組込みマイコンにソフトウェアをインプリメントする前に、予めPCベースで確認してみようと思います。
まずはFONTX形式を勉強します。
FONTの構造がマイコンで利用しやすい形式ならば、そのままマイコンから利用してしまおうと思います。
しかしそうでなければ、一度変換してしまったほうがいいかもしれません。
FONTXといっても、フォントファイルがなければ始まりません。
まずは、恵梨沙フォントを試してみようと思います。
このフォントは元々HPの小型PC、HP95LXの為に作成された、8x8ドット構成であるにも関わらず
判読性の良いフォントです。
また個人的な使用に関しては無償利用を認めてくださっています。
ソニーのネットワークウォークマンにも使われているそうです。
まずは、恵梨沙フォントページより、オリジナル形式のフォントファイルを入手します。
次に、Natrium氏のホームページより、ふぉんと昆布(FONTCONV)をダウンロードします。
次に、恵梨沙フォントをふぉんと昆布でFONTX2形式に変換しましょう。
ダウンロードしたフォントファイルELISA100.FNTと、ふぉんと昆布を
同じフォルダにコピーして、コマンドラインから以下のように入力します。
C:\Font>fontconv /E08 ELISA100.FNT ELISA100.FON
(C:\Fontというフォルダに格納した場合のコマンドラインイメージです。
この操作でFONTX形式の恵梨沙フォントができました。
次に、24x24ドットのファイルも実験してみるべく、
力武 健次氏のJIS 24x24FONT for $FONTXもダウンロードしてみます。
このファイルは既にFONTX形式なので、特に変換はいりません。
準備は以上です。
gccから実際にフォントにアクセスしてみたいと思います。
フォントの構造などは上記ページに詳細が掲載されていますので、そちらを参考にしてください。
で、試しにフォントにアクセスするソースを作成してみました。
考えながら超適当に作ったので汚いソースですが、時間があれば整理します。
fontx_ana.cpp
MinGW版gcc(on Windows)で動作確認しています。(実行ファイル)
このプログラムは、最低8x8ドット、最大48x48ドット、横幅が8の倍数になるフォントのみ
対応しています。
祝!動きました。
FONTX2のフォント形式には、漢字フォント用とASCIIフォント(主に半角)用があり、ヘッダ部と文字データの並びに違いがあります。
ASCIIフォントは、素直に文字データがASCIIコード順に並んでいるのに対して、漢字フォントはコード内に文字の存在しない領域があるので、文字の存在する部分ごとにブロックを分け、ヘッダ内に存在する文字コードと対応するビットマップ領域のテーブルを参照して表示させます。
以降、漢字フォントとASCIIフォントを別々に解説します。
FONTX形式は、大きく分けて、データの中身の構造を記述してあるヘッダ部と、フォントデータそのものが入っているデータ部の二つのブロックに分かれます。
gccである程度アクセスができるようになったので、
FONTXファイルの構造がわかってきました。
構造を紹介します。
struct {
char Identifier[6]; // "FONTX2"という文字列が入る
char FontName[8]; // Font名(8文字)
unsigned char XSize; // フォントの横幅
unsigned char YSize; // フォントの高さ
unsigned char CodeType;
unsigned char Tnum; // 文字コードテーブルのエントリ数
struct {
unsigned short Start; // 領域の始まりの文字コード(SJIS)
unsigned short End; // 領域の終わりの文字コード(SJIS)
} Block[]; // Tnum個続く
};
C言語構造体でのイメージ
ドットフォントデータのファイル先頭からの開始位置は、文字コード範囲のデータ
量(=Tnum)がフォント毎に異なるために、それによって変化します。
この開始位置は
フォントデータの先頭アドレス = 18 + Tnum * 4;
とあらわされます。
18とは、先頭部分ヘッダの文字コードエントリより前の部分までのサイズで、
Tnum*4とは文字コードの範囲を示すデータのサイズです。
この二つの値の和のサイズ分フォントファイル先頭からヘッダのデータとして
格納されており、それ以降は実フォントデータになっています。
(実フォントについては実フォントデータの項目参照)
文字データにアクセスするには、上記の漢字フォントヘッダ構造体でのBlock[n].StartとBlock[n].Endと、実際に表示したいSJIS文字コードを比較します。例えば、SHIFT-JIS文字コード0x81a0のビットマップのスタート領域を知りたい場合は、以下のようにします。
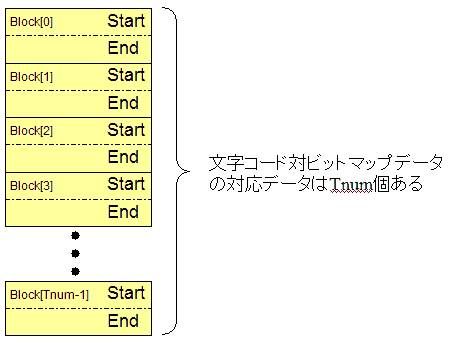 まず、Blockという領域は、StartとEndで構成されていて、Tnum個存在します。
まず、Blockという領域は、StartとEndで構成されていて、Tnum個存在します。
表示したいSJIS文字コードがどのBlockに存在するか調べます。
int SearchFontAreaNo_Kanji(unsigned short code){
int i;
int ret;
for (i=0;i<font->Tnum;i++){
if((font->Block[i].Start <= code) && (font->Block[i].End >= code)){
return(i);
}
}
return (-1);
}
この関数では、指定した文字コードがどのBlockに存在するかチェックし、結果を返します。
もし対応するBlockがBlock[0〜(Tnum-1)]の範囲に見つからなかった場合、-1を返します。
実際の文字ビットマップデータは、ヘッダの終わった部分の次から始まります。
この部分を始点として、以下の式で表されます。
表示したい文字の文字コードをC、表示したい文字が存在するBlockをTとした場合、
スタートアドレス(単位:bytes) =
文字ビットマップデータ始点 + {(Σk=0T-1(Block[k].Start - Block[k].End)) + (C - Block[T])} * 1フォント辺りのサイズ(単位:bytes)
では、アスキー文字のFONTX2データの構造を紹介します。
typedef struct {
char Identifier[6]; // "FONTX2"という文字列が入る
char FontName[8]; // Font名(8文字)
unsigned char XSize; // フォントの横幅
unsigned char YSize; // フォントの高さ
unsigned char CodeType; // 0x01
};
C言語構造体でのイメージ
ASCII文字のフォントデータは、上記構造体のヘッダのCodeTypeの次のバイトよりアスキーコード0x00のデータが始まります。
(あとでちゃんと説明させていただきます)
FONTX2フォーマットでは、フォントの1ドットは1ビットで構成されています。
(2値データということです。
フォントは、((x,y);x:横方向、y:縦方向とした場合)文字の左上のピクセルを(0,0)、右下が(16,16)であれば、
フォントデータは以下のようになります。
1バイト目 : (0,0)-(7,0)の8ビットデータ
2バイト目 : (8,0)-(15,0)の8ビットデータ
3バイト目 : (0,1)-(7,1)の8ビットデータ
4バイト目 : (8,1)-(15,1)の8ビットデータ
5バイト目 : (0,2)-(7,2)の8ビットデータ
6バイト目 : (8,2)-(15,2)の8ビットデータ
・・・
31バイト目 : (0,15)-(7,15)の8ビットデータ
32バイト目 : (8,15)-(15,15)の8ビットデータ
(のちほどきちんと説明します。ちなみに縦方向のドット数が増えるばあいには、
そのままデータがもっとつづくだけですし、横方向に長くなる場合もライン毎のデータ
が大きくなるだけです。