堦岥偵夋憸張棟偲尵偭偰傕丄柧傞偝傗僐儞僩儔僗僩傪挷惍偟偨傝丄傏偐偟偨傝丄慛柧偵偟偨傝偡傞側偳丄條乆側夋憸張棟偑偁傝傑偡丅 偙傟傜偺夋憸張棟偼丄HSP偺PSET柦椷偲PGET柦椷傪嬱巊偡傟偽丄僾儔僌僀儞傪巊傢偢偵幚尰偡傞帠傕晄壜擻偱偼偁傝傑偣傫丅 偟偐偟丄僾儔僌僀儞傪巊傢偢偵HSP偩偗偱幚尰偟傛偆偲偡傞偲丄張棟偵帪娫偑偐偐偭偰偟傑偄傑偡丅 偦偙偱丄VRAM傪捈愙憖嶌偡傞帠偱崅懍偵夋憸張棟傪峴偆僾儔僌僀儞傪嶌偭偰傒傑偟傚偆丅
VRAM傪捈愙憖嶌偡傞帠偱夋憸張棟傪峴偆偨傔偵偼丄傑偢VRAM偲偼偳偆偄偆傕偺側偺偐偵偮偄偰抦偭偰偍偐側偗傟偽側傝傑偣傫丅 偙傟偵偮偄偰偼丄乽HSP偐傜偺DLL屇傃弌偟曽朄儕僼傽儗儞僗儅僯儏傾儖乿偵彂偐傟偰偄傞偺偱偦偪傜傪撉傫偱偔偩偝偄丅
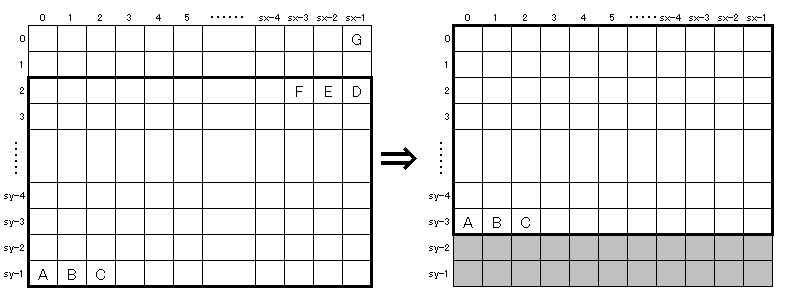
娙扨側夋憸張棟偺椺偲偟偰丄僂僀儞僪僂撪偺夋憸傪忋偵僗僋儘乕儖偝偣傞rollup柦椷傪嶌偭偰傒傑偟傚偆丅 偙傟傪嶌偭偰偍偗偽丄僎乕儉偺僄儞僨傿儞僌側偳偵棙梡偱偒偦偆偱偡丅 壗僪僢僩忋偵僗僋儘乕儖偝偣傞偐偼丄p2偱巜掕偡傞帠偵偟偨偄偲巚偄傑偡丅 乮p1偼BMSCR峔憿懱傊偺億僀儞僞偱偡丅乯 傑偢偼丄偳偺傛偆偵偡傟偽椙偄偐峫偊偰傒傑偟傚偆丅
壖偵丄p2偺抣傪2偲偟偰峫偊偨偺偑壓偺恾偱偡丅 墶偺僪僢僩悢偼sx丄廲偺僪僢僩悢偼sy偱偡丅 偙傟傪忋偵2僪僢僩僗僋儘乕儖偝偣傞偲偄偆偙偲偼丄懢榞偺晹暘傪堏摦偡傞帠偵側傝傑偡丅 懢榞偺晹暘傪偳偺傛偆偵偟偰堏摦偡傞偐偱偡偑丄揰A丄揰B丄揰C丄乧偺弴偵壓偐傜堏摦偟偰偄偔偺偼岆傝偱偡丅 堦斣壓偺2峴偺堏摦偑廔傢偭偰3峴栚偺堏摦傪巒傔傞帪丄3峴栚偵偁傞偺偼尦乆3峴栚偵偁偭偨夋憸偱偼側偔丄1峴栚偐傜堏摦偝傟偰偒偨夋憸偩偐傜偱偡丅 廬偭偰丄揰D丄揰E丄揰F丄乧偺弴偵忋偐傜堏摦偟偰偄偐側偗傟偽側傝傑偣傫丅 媡偵丄忋偵僗僋儘乕儖偡傞偺偱偼側偔壓偵僗僋儘乕儖偡傞応崌偼丄忋偐傜偱偼側偔壓偐傜堏摦偟偰偄偐側偗傟偽側傝傑偣傫丅
堏摦偡傞弴斣偑暘偐偭偨傜丄師偼堏摦偡傞僶僀僩悢傪峫偊偰傒傑偟傚偆丅 偙偙偱偼丄僷儗僢僩儌乕僪偱偼側偔僼儖僇儔乕儌乕僪偱弶婜壔偝傟偰偄傞傕偺偲偟傑偡丅 僼儖僇儔乕儌乕僪偺応崌丄1僪僢僩偵偮偒R,G,B偺3僶僀僩偱1僪僢僩偺怓傪昞偟傑偡偐傜丄墶偺僪僢僩悢偑sx丄廲偺僪僢僩悢偑sy偱偁傟偽3*sx*(sy-p2)偵側傝傑偡偹丅
師偵丄堦斣嵟弶偵堏摦偡傞揰D偺傾僪儗僗傪峫偊偰傒傑偟傚偆丅 夋柺忋偺擟堄偺揰(x,y)偺怓偑擖偭偰偄傞傾僪儗僗偼丄
惵偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - 1 - y ) * sx * 3 } + ( x * 3 )偱偡偐傜丄揰D(sx-1,p2)偺傾僪儗僗偼
椢偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - 1 - y ) * sx * 3 } + ( x * 3 ) + 1
愒偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - 1 - y ) * sx * 3 } + ( x * 3 ) + 2
惵偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - p2 ) * sx * 3 } - 3
椢偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - p2 ) * sx * 3 } - 2
愒偺擹搙抣偺傾僪儗僗 = pBit + { ( sy - p2 ) * sx * 3 } - 1
偲側傝傑偡丅 廬偭偰丄pBit + { ( sy - p2 ) * sx * 3 } - 1偐傜弴偵堏摦偟偰偄偗偽偄偄帠偑暘偐傝傑偡丅
師偵丄堦斣嵟弶偵堏摦偡傞揰偺堏摦愭偺傾僪儗僗傪峫偊偰傒傑偟傚偆丅 堦斣嵟弶偵堏摦偡傞揰偺堏摦愭偼揰G(sx-1,0)偱偡偐傜丄
惵偺擹搙抣偺傾僪儗僗 = pBit + ( 3 * sx * sy ) - 3
椢偺擹搙抣偺傾僪儗僗 = pBit + ( 3 * sx * sy ) - 2
愒偺擹搙抣偺傾僪儗僗 = pBit + ( 3 * sx * sy ) - 1
偲側傝傑偡丅 廬偭偰丄pBit + ( 3 * sx * sy ) - 1偐傜弴偵堏摦偟偰偄偗偽偄偄帠偑暘偐傝傑偡丅
崱寁嶼偟偨抣傪偦傟偧傟ecx儗僕僗僞丄esi儗僕僗僞丄edi儗僕僗僞偵奿擺偟丄std柦椷傪幚峴偟偨忋偱乽rep movsb乿傪幚峴偡傟偽丄僂僀儞僪僂撪偺夋憸傪忋偵僗僋儘乕儖偝偣傞帠偑偱偒傑偡丅 扐偟丄VRAM忋偺夋憸僨乕僞傪憖嶌偟偨偩偗偱偼幚嵺偺僂僀儞僪僂偵偼斀塮偝傟側偄偨傔丄幚嵺偺僂僀儞僪僂偵斀塮偝偣側偗傟偽側傝傑偣傫丅 幚嵺偺僂僀儞僪僂偵斀塮偝偣傞偵偼HSP偺redraw柦椷傪巊梡偡傞偺偑娙扨偱偡偑丄偙偙偱偼戞係復偱bms_send傪堏怉偟偨傛偆偵bms_update傪堏怉偟偰傒傑偟偨丅 側偍丄堏摦屻偺恾偺奃怓偺晹暘偼偦偺傑傑偵偟偰偁傝傑偡偺偱丄昁梫偵墳偠偰boxf柦椷偱揾傝捵偡摍偟偰偔偩偝偄丅
崱愢柧偟偨帠傪尦偵嶌惉偟偨偺偑壓偺僾儘僌儔儉偱偡丅 僗僋儘乕儖偝偣傞庤弴偵偮偄偰偼崱愢柧偟偨偺偱丄傑偩愢柧偟偰偄側偄柦椷偩偗傪愢柧偟傑偡丅
傑偢丄慜偺曽偵乽bm equ [esi].BMSCR乿偲偄偆偺偑弌偰偒傑偡丅 偙偺equ偲偄偆偺偼HSP偺#define柦椷偲慡偔摨偠摥偒傪偡傞傕偺偱丄乽bm乿偲偄偆柤慜偑弌偰偒偨傜乽[esi].BMSCR乿偵抲偒姺偊偰傾僙儞僽儖偟側偝偄丄偲傾僙儞僽儔偵柦椷偟偰偄傞偺偱偡丅 偙偺傛偆偵偡傞帠偱丄BMSCR峔憿懱傪嶲徠偡傞偨傃偵乽[esi].BMSCR乿偲彂偔庤娫偑徣偗傑偡丅
rollup偺拞偱巊梡偟偰偄傞mul柦椷偼妡偗嶼傪偡傞柦椷側偺偱偡偑丄偙傟偑彮偟栵夘偱偡丅 懌偟嶼傪峴偆add柦椷傗堷偒嶼傪峴偆sub柦椷偵偼僆儁儔儞僪偑2偮偁傝傑偡偑丄偙偺mul柦椷偵偼僆儁儔儞僪偑1偮偟偐偁傝傑偣傫丅 偱偼丄僆儁儔儞僪偺抣偲壗偺抣傪妡偗傞偺偐偲偄偆偲丄僆儁儔儞僪偑8價僢僩偺応崌偼al儗僕僗僞丄16價僢僩偺応崌偼ax儗僕僗僞丄32價僢僩偺応崌偼eax儗僕僗僞偲偺妡偗嶼偑峴傢傟傑偡丅 妡偗嶼傪偟偨寢壥偼丄僆儁儔儞僪偑8價僢僩偺応崌al儗僕僗僞偵擖傞傢偗偱傕僆儁儔儞僪偵擖傞傢偗偱傕側偔丄ax儗僕僗僞偵擖傝傑偡丅 傑偨丄僆儁儔儞僪偑16價僢僩偺応崌偼丄妡偗嶼傪偟偨寢壥偺壓埵16價僢僩偑ax儗僕僗僞偵丄忋埵16價僢僩偑dx儗僕僗僞偵擖傝傑偡丅 僆儁儔儞僪偑32價僢僩偺応崌偼丄妡偗嶼傪偟偨寢壥偺壓埵32價僢僩偑eax儗僕僗僞偵丄忋埵32價僢僩偑edx儗僕僗僞偵擖傝傑偡丅 壓偺僾儘僌儔儉偱偼戝偒側抣傪偐偗偰偄傞傢偗偱偼側偔丄忋埵32價僢僩偑0偵側傞帠偼柧傜偐偱偁傞偙偲偐傜丄妡偗嶼傪偟偨屻偺edx儗僕僗僞偺抣偼柍帇偟偰偄傑偡丅
sub柦椷偼丄戞堦僆儁儔儞僪偺抣偐傜戞擇僆儁儔儞僪偺抣傪堷偄偨抣傪丄戞堦僆儁儔儞僪偵戙擖偡傞柦椷偱偡丅 dec柦椷偼丄僆儁儔儞僪偺抣傪1偩偗尭傜偡柦椷偱偡丅
|
|
偝偰丄忋偺僒儞僾儖傪幚峴偡傞偲丄堄恾偟偨捠傝僂僀儞僪僂撪偺恾宍偑忋傊僗僋儘乕儖偟偰偄偒傑偡偹丅 傔偱偨偟傔偱偨偟丒丒丒 偲尵偄偨偄偲偙傠側偺偱偡偑丄screen柦椷偺僷儔儊乕僞傪乽0,639,480,0.0,0,639,480乿偵曄偊偰傒傞偲丒丒丒 偁傟傟丠嵍幬傔忋偵僗僋儘乕儖偟偰偟傑偄傑偡偹丅 傑偨丄screen柦椷偺僷儔儊乕僞傪乽0,638,480,0.0,0,638,480乿偵曄偊偰傒傞偲丄怓偑曄壔偟側偑傜嵍幬傔忋偵僗僋儘乕儖偟偰偟傑偄傑偡丅 堦懱壗偑娫堘偭偰偄傞偺偱偟傚偆偐丠
HSP偺僾儔僌僀儞偺嶌惉偵偮偄偰夝愢偟偰偄傞僒僀僩傪専嶕偟偰傒偨偲偙傠丄乽HSP偐傜偺DLL屇傃弌偟曽朄儕僼傽儗儞僗儅僯儏傾儖乿偵婰嵹偝傟偰偄傞乽pBit + { ( sy - 1 - y ) * sx * 3 } + ( x * 3 )乿偲偄偆幃偼丄墶偺僪僢僩悢乮sx偺抣乯偑4偺攞悢偺帪偵偟偐惉傝棫偨側偄帠偑暘偐傝傑偟偨丅 崱傑偱丄1峴偺僶僀僩悢偼3*sx偱偁傞偲偄偆慜採偱夝愢偟傑偟偨偑丄偙偺3*sx偲偄偆抣偑4偺攞悢偱偼側偄応崌丄1峴偺僶僀僩悢偑4偺攞悢偵側傞傛偆偵僟儈乕偺僶僀僩偑憓擖偝傟偰偄傞偺偱偡丅
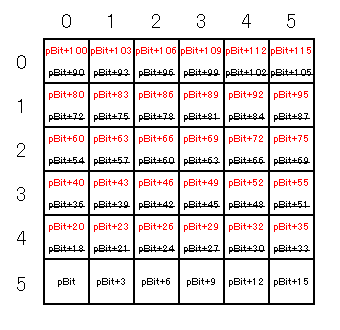
偲尵偭偰傕暘偐傝偵偔偄偱偟傚偆偐傜丄嬶懱揑側椺偱愢柧偟傑偟傚偆丅
壖偵sx=6丄sy=6偩偭偨偲偟傑偡丅
揰(0,5)偺怓偼pBit丄pBit+1丄pBit+2偵擖偭偰偄傑偡丅
揰(1,5)偺怓偼pBit+3丄pBit+4丄pBit+5偵擖偭偰偄傑偡丅
乧乧
揰(5,5)偺怓偼pBit+15丄pBit+16丄pBit+17偵擖偭偰偄傑偡丅
偲丄偙偙傑偱偼椙偄偺偱偡偑丄揰(0,4)偺怓偼pBit+18丄pBit+19丄pBit+20偵擖偭偰偄傞傢偗偱偼偁傝傑偣傫丅 3*sx偼18偱偁傝丄4偺攞悢偱偼側偄偨傔丄4偺攞悢偵側傞傛偆偵僟儈乕偺僶僀僩偑2僶僀僩擖偭偰偄傑偡丅 偙偺椺偺応崌丄pBit+18偲pBit+19偑僟儈乕偱偡丅 廬偭偰丄揰(0,4)偺怓偼pBit+20丄pBit+21丄pBit+22偵擖偭偰偄傑偡丅
偆傑偔僗僋儘乕儖偝傟側偐偭偨尨場偑暘偐偭偨偺偱丄偆傑偔僗僋儘乕儖偝傟傞傛偆偵廋惓偟傑偟傚偆丅 傑偢丄3*sx偺抣偑4偺攞悢偐偳偆偐傪挷傋傑偡丅 壓偺僾儘僌儔儉偱偼丄3*sx偺抣乮eax偺抣乯偲3偲偺榑棟榓偑0偐偳偆偐傪挷傋傞帠偱丄3*sx偺抣偑4偺攞悢偐偳偆偐傪挷傋偰偄傑偡丅 榑棟榓傪媮傔傞偵偼and柦椷傪巊偭偰傕椙偄偺偱偡偑丄偙偺椺偺傛偆偵摿掕偺價僢僩偑0偐1偐傪挷傋傞栚揑偱榑棟榓傪媮傔傞応崌偵偼丄and柦椷偱偼側偔test柦椷傪巊偄傑偡丅 and柦椷偱偼丄戞堦僆儁儔儞僪偲戞擇僆儁儔儞僪偺榑棟榓偑寁嶼偝傟丄偦偺抣偑戞堦僆儁儔儞僪偵戙擖偝傟傑偡丅 偦傟偵懳偟偰test柦椷偱偼丄戞堦僆儁儔儞僪偲戞擇僆儁儔儞僪偺榑棟榓偑寁嶼偝傟傑偡偑丄偦偺抣偼偳偙偵傕戙擖偝傟傑偣傫丅 榑棟榓偑0偐偳偆偐偵傛偭偰暘婒偟偨偄帪偵丄jz柦椷傗jnz柦椷偲嫟偵梡偄傑偡丅
4偺攞悢偐偳偆偐傪挷傋偨寢壥4偺攞悢偩偲暘偐偭偨傜丄僟儈乕偺僶僀僩悢傪壛偊傑偡丅 壓偺僾儘僌儔儉偱偼丄壓埵2價僢僩傪0偵偟偰偐傜4傪懌偟偰偄傑偡丅 側偤壓埵2價僢僩傪0偵偟偰偐傜4傪懌偡偙偲偱僟儈乕偺僶僀僩悢傪壛偊偨帠偵側傞偐偼丄帺暘偱峫偊偰傒偰偔偩偝偄丅 2恑悢偵偮偄偰椙偔棟夝偟偰偄側偄偲擄偟偄偲巚偄傑偡偑丄2恑悢偵偮偄偰椙偔棟夝偟偰偄傟偽暘偐傞偲巚偄傑偡丅
|
|
偲偙傠偱丄堦懱側偤偙傫側傗傗偙偟偄峔憿偵側偭偰偄傞偺偱偟傚偆偐丠 側偤1峴偺僶僀僩悢偑4偺攞悢偵側傞傛偆偵傢偞傢偞僟儈乕偺僶僀僩偑壛偊傜傟偰偄傞偺偱偟傚偆偐丠 偦傟偵偼丄2偮偺棟桼偑峫偊傜傟傑偡丅
堦偮偼丄movsb傪巊偆曄傢傝偵movsd傪巊偆帠偑偱偒傞偲偄偆帠偱偡丅 movsb傪4夞幚峴偟側偔偰傕丄movsd傪1夞幚峴偡傞偩偗偱4僶僀僩堏摦偡傞帠偑偱偒傞偺偱丄堏摦偺夞悢傪尭傜偡帠偑偱偒傑偡丅 堏摦偺夞悢傪尭傜偡帠偑偱偒傞偨傔丄庒姳崅懍壔偡傞帠偑偱偒傑偡丅
傕偆堦偮偼丄4僶僀僩嫬奅傪傑偨偖帠偑旔偗傜傟傞偲偄偆帠偱偡丅 偣偭偐偔movsd傪巊偭偰4僶僀僩扨埵偱堏摦偟偰傕丄movsd傪幚峴偡傞偨傃偵4僶僀僩嫬奅傪傑偨偄偱偄偰偼丄偦傟偩偗懍搙偑掅壓偟偰偟傑偄傑偡丅 偦偙偱丄1峴偺僶僀僩悢偑4偺攞悢偵側傞傛偆偵偡傞偙偲偱丄4僶僀僩嫬奅傪傑偨偖偺傪杊偄偱偄傞偲峫偊傜傟傑偡丅
崱弎傋偨擇偮偺棟桼偼丄偁偔傑偱傕杔偺悇應偵偡偓傑偣傫丅 廬偭偰丄昁偢偟傕偙偺擇偮偺棟桼偑杮摉偺棟桼偱偁傞偲偄偆曐徹偼偁傝傑偣傫偺偱偛椆彸偔偩偝偄丅 傑偨丄乽4僶僀僩嫬奅乿偲偄偆暦偒姷傟側偄尵梩偑弌偰偒傑偟偨偑丄偙傟偵偮偄偰偼俙們倕丏俲巵偺HP偵偁傞乽婾儅僔儞岅島嵗乿傪嶲徠偟偰偔偩偝偄丅
偝偰丄崱弎傋偨悇應偑惓偟偗傟偽丄movsb傪巊偆曄傢傝偵movsd傪巊偆帠偱崅懍壔偡傞帠偑偱偒傑偡偹丅 偦偙偱丄movsb偺戙傢傝偵movsd傪巊偆傛偆偵僾儘僌儔儉傪廋惓偟偰傒傑偟傚偆丅 偙偙偱shr偲偄偆柦椷傪巊偭偰偄傑偡偑丄偙傟偼戞堦僆儁儔儞僪偺抣傪塃偵僔僼僩偡傞柦椷偱偡丅 壗價僢僩僔僼僩偡傞偐偼丄戞擇僆儁儔儞僪偱巜掕偟傑偡丅
movsb偺戙傢傝偵movsd傪巊偆帠偱偳傟偩偗崅懍壔偟偨偐丄幚峴偟偰斾妑偟偰傒傑偟偨丅 杦偳嵎偼偁傝傑偣傫偱偟偨偑丄repeat柦椷偺儖乕僾夞悢傪憹傗偟偰傒傞偲丄傎傫偺彮偟偩偗崅懍壔偟偨傛偆偱偡丅
|
|