|
|
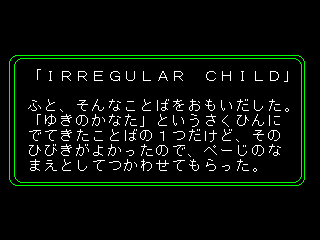
MESSAGE.DAT 表示画面.PNG CONV_SMP.EXE CONV_SMP.CPP CONV_SMP.TBL |
… 独自の文字コードを用いたメッセージデータ。 … メッセージデータを表示している画面の画像(上の画像と同じものです) … MESSAGE.DATを読み込んでテキストを出力するコンバータ本体サンプル。 … コンバータ本体のC++ソースコード。 … コンバータで利用する変換用フォントテーブル。 |
-- BYTE型 文字コード検索 -- ファイル読み込み ... 完了 データ解析開始 (候補発見 001) OFFSET 00000001 : 12 1b 1b 0e 10 1e 15 0a 1b 文字列テーブル出力(アルファベット) A:0a B:0b C:0c D:0d E:0e F:0f G:10 H:11 I:12 J:13 K:14 L:15 M:16 N:17 O:18 P:19 Q:1a R:1b S:1c T:1d U:1e V:1f W:20 X:21 Y:22 Z:23 差異 : SJIS A(0x41) - 0x0a = 0x37 解析終了これで英字の文字コードが取得できましたが、さらにカッコやスペースの文字コードも調べてしまいましょう。
-- フィルタリング出力(ログ) -- 範囲 : 00000000 〜 00000010 バイトサイズ : 1(半角文字) 基準値 : 37 (加算) == オフセット & 16進データ付加出力 == 00000000 : 24 [ 00000001 : 12 I 00000002 : 1B R 00000003 : 1B R 00000004 : 0E E 00000005 : 10 G 00000006 : 1E U 00000007 : 15 L 00000008 : 0A A 00000009 : 1B R 0000000A : 28 _ 0000000B : 0C C 0000000C : 11 H 0000000D : 12 I 0000000E : 15 L 0000000F : 0D D 00000010 : 25 \ 出力完了これによって、カッコ(「) → 24、スペース → 28、カッコ閉じ(」) → 25であるということが判明します。
現段階のフォントテーブル *=未知 / □=スペース
+0+1+2+3+4+5+6+7+8+9+A+B+C+D+E+F 00 **********ABCDEF 10 GHIJKLMNOPQRSTUV 20 WXYZ「」**□******* |
-- BYTE型 文字コード検索 -- ファイル読み込み ... 完了 データ解析開始 (候補発見 001) OFFSET 00000013 : 4b 43 26 3e 5d 44 39 43 文字列テーブル出力(半角カナ 暫定) ア:30 イ:31 ウ:32 エ:33 オ:34 カ:35 キ:36 ク:37 ケ:38 コ:39 サ:3a シ:3b ス:3c セ:3d ソ:3e タ:3f チ:40 ツ:41 テ:42 ト:43 ナ:44 ニ:45 ヌ:46 ネ:47 ノ:48 ハ:49 ヒ:4a フ:4b ヘ:4c ホ:4d マ:4e ミ:4f ム:50 メ:51 モ:52 ヤ:53 ユ:54 ヨ:55 ラ:56 リ:57 ル:58 レ:59 ロ:5a ワ:5b ン:5c 差異 : KANA ア(0xb1) - 0x30 = 0x81 解析終了オフセット 00000013 にヒットしました。
-- フィルタリング出力(ログ) -- 範囲 : 11 〜 66 バイトサイズ : 1(半角文字) 基準値 : 81 (加算) == オフセット & 16進データ付加出力 == 00000011 : FF 00000012 : FF 00000013 : 4B フ 00000014 : 43 ト 00000015 : 26 ァ 00000016 : 3E ソ 00000017 : 5D 00000018 : 44 ナ 00000019 : 39 コ 0000001A : 43 ト 0000001B : 6F 0000001C : 5C ン 0000001D : 34 オ 0000001E : 52 モ 0000001F : 31 イ | 00000020 : 6A 00000021 : 3B シ 00000022 : 3F タ 00000023 : 27 ィ 00000024 : FF 00000025 : 24 00000026 : 54 ユ 00000027 : 36 キ 00000028 : 48 ノ 00000029 : 35 カ 0000002A : 44 ナ 0000002B : 3F タ 0000002C : 25 ヲ 0000002D : 43 ト 0000002E : 31 イ 0000002F : 32 ウ 00000030 : 3A サ 00000031 : 37 ク 00000032 : 4A ヒ 00000033 : 5D | 00000034 : 45 ニ 00000035 : FF 00000036 : 6D 00000037 : 42 テ 00000038 : 36 キ 00000039 : 3F タ 0000003A : 39 コ 0000003B : 43 ト 0000003C : 6F 0000003D : 48 ノ 0000003E : 01 0000003F : 41 ツ 00000040 : 6A 00000041 : 38 ケ 00000042 : 6E 00000043 : 26 ァ 00000044 : 3E ソ 00000045 : 48 ノ 00000046 : FF 00000047 : 4A ヒ | 00000048 : 70 00000049 : 36 キ 0000004A : 60 0000004B : 55 ヨ 0000004C : 35 カ 0000004D : 5E 0000004E : 3F タ 0000004F : 48 ノ 00000050 : 6D 00000051 : 26 ァ 00000052 : 77 00000053 : 5F 00000054 : 66 00000055 : 48 ノ 00000056 : 44 ナ 00000057 : FF 00000058 : 4E マ 00000059 : 33 エ 0000005A : 43 ト 0000005B : 3B シ | 0000005C : 42 テ 0000005D : 41 ツ 0000005E : 35 カ 0000005F : 5B ワ 00000060 : 3D セ 00000061 : 42 テ 00000062 : 52 モ 00000063 : 56 ラ 00000064 : 5E 00000065 : 3F タ 00000066 : 27 ィ 出力完了 |
現段階のフォントテーブル *=未知 / □=スペース
+0+1+2+3+4+5+6+7+8+9+A+B+C+D+E+F 00 *1********ABCDEF 10 GHIJKLMNOPQRSTUV 20 WXYZ「」**□******* 30 あいうえおかきくけこさしすせそた 40 ちつてとなにぬねのはひふへほまみ 50 むめもやゆよらりるれろわをんっー 60 が*****じ***だ**でどば 70 び******ぺ******** |