



オブジェクト指向プログラミングと対比されるものとして、手続き型のほかに、データ中心指向があります。データ中心指向は、大量のデータを扱う業務アプリケーションで適用される方法論で、機能や処理を中心に考えるのではなく、データを中心に考えていくアプローチです。機能や処理に比べてデータは不変であるため、データが重要な意味を持ってくる業務アプリケーションでは、この考え方が適しています。
オブジェクト指向との違いは何かというと、簡単に言えば、オブジェクトを中心に考えるか、データベースを中心に考えるかの違いです。
ドメインを中心に考えている点では、どちらも一緒です。ドメインとは、アプリケーションが解決しようとしている問題領域のことです。ドメインを明確にする際、モデルが作成されます。モデルは、その問題領域で扱うデータを構造化し、関連を明確にし、アプリケーションの本質的な部分、骨子を明確にしていくものです。そのため、両者とも機能や処理を中心に考える手続き型とは一線を画しています。
相違点は以下の点を挙げることができます。
データ中心指向では、データモデルが適用され、その表現としてER図やDFDが用いられます。オブジェクト指向では、オブジェクトモデルが適用され、その表現としてUML(クラス図やアクティビティ図など)が用いられます。
そのモデル内部で使われる用語も異なり、データモデルでエンティティやテーブルと呼ばれるものが、オブジェクトモデルではクラスやオブジェクトと呼ばれます。またエンティティ間の関連を表す仕方も異なっています。ただしオブジェクト指向ではUMLで標準化されているのに対して、データモデルの表現の仕方は様々な流派によって異なります。
また、エンティティの属性に、データモデルでは識別キーを記述するのに対して、オブジェクトモデルでは記述しません。これは実装レベルの問題に関連してくるのですが、データベースでは単なる表であるため、識別キーがないと各エンティティを区別できないのに対して、オブジェクトではインスタンスを生成した際に自動的にIDが割り振られるため、あえてモデルに記述する必要がないからです。
キーについては、特に複合キーになってくると違いが鮮明になってきます。データモデルでは一意にエンティティを識別するために二つ以上の属性を必要とすることがあります。オブジェクトではその必要はありません。
また関連についても、データモデルでは参照キーが属性に書かれるのに対して、クラス図では関連するオブジェクトについては線で関連が表現されているため、属性に書くことはありません。それぞれが独立したエンティティであるため、その参照は「属性」として記述するのは不適切であるからです。
このモデルの違いは、設計思想の違いに絡んできます。
データモデルでは、エンティティと属性そして他のエンティティとの関連を記述できますが、オブジェクトモデルではさらに手続きを記述することができます。データ中心指向では、あくまでもデータはデータ、処理は処理と分離されているのに対して、オブジェクト指向ではデータに関連する処理は同じ箇所に記述するようになっています。そのため、オブジェクトモデルでは、描いたクラス図からソースコードに落とすことができます。逆にソースコードからクラス図を起こす(リバースエンジニアリング)ことができます。プログラムは、オブジェクトの連携として表現され、処理はオブジェクトの内部にあるため、データ中心指向のようにデータを設計した後に、そのデータにアクセスする処理を検討するという形態ではないのです。
データ中心指向でもオブジェクト指向でも、物理的なストレージ(永続記憶装置)としてデータベースを用います。しかし、その位置づけは大きく異なっています。データ中心指向もオブジェクト指向も概念モデルからはじめて、物理モデル(=実装レベル)に移行します。データ中心指向では最終的な設計レベルはデータベース設計であるのに対して、オブジェクト指向ではクラス図です。
オブジェクト指向でも、扱ったデータは保存する必要があるため(メモリでは障害発生時に消えてしまう)、そのオブジェクトで保持しているデータをデータベースに格納する作業が必要になります。結局そこでデータベース設計が必要になるのですが、あくまでもデータベースはオブジェクトを記憶装置に保存するだけのもので脇役に過ぎません。
それに対して、データ中心指向ではデータベースは要の中の要となり、アプリケーションの作成は、常にデータベース設計を参照しながら行われます。
先ほども述べたとおり、オブジェクト指向プログラミングではデータとそれに関連する処理をセットで考え、アプリケーションの中では各オブジェクトが連携して機能を実現していく形をとります。
一方、データ中心指向プログラミングでは、データと処理が分離されているため、処理を行うモジュールとデータを保持するオブジェクトとが別になっています。
どちらもデータベースにアクセスする必要があります。そのアクセスにはSQLを用います。SQLはデータベースにアクセスして、データの更新や検索などを行うのに最適で構造化された言語で、個人的にはSQLは最もシンプルで必要な情報をすべて盛り込めるよい言語だと思います。しかし、SQLはオブジェクト指向言語とは形態が異なります。
例えばあるデータの集合から、指定したデータを検索して取り出してくるメソッドを考えます。
オブジェクト指向では、JavaであればJava言語を使ってそのロジックを追っていくことができます。データへのアクセスは、Java言語のメソッドを使って行います。
List emps = new ArrayList();
for (Iterator i = list.iterator(); i.hasNext();) {
Employee e = (Employee)i.next();
if (e.getDeptno() == 18) {
emps.add(e);
}
}
return emps;
Criteria crit = session.createCriteria(Employee.class);
crit.add(Expression.eq("deptno", 18));
List emps = crit.list();
return emps;
それに対して、SQLを使った場合、Java言語でロジックを追いかけていくことができません。SQLがわからないJavaプログラマーにとって何をやっているのかわからないのです。
String sql = "select EMPNO, EMPNAME, MEMO from EMPLOYEE where DEPTNO=?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 18);
ResultSet rs = pstmt.executeQuery();
List emps = new ArrayList();
if (rs.next()) {
Employee emp = new Employee();
emp.setEmpno(rs.getInt("EMPNO"));
emp.setEmpname(rs.getString("EMPNAME"));
emp.setMemo(rs.getString("MEMO"));
emps.add(emp);
}
return emps;
最初の一行で、どのデータをとっているのかをSQLで表現しています。その後は、パラメータのセット、SQLの実行およびデータの取得となります。検索ロジックはSQLに表現されています。
SQLぐらいわかっているのが当たり前だとデータ中心指向の人は考えるのですが、オブジェクト指向の人はそうは考えません。特に複雑なSQLが用いられるようになると解読が困難になります。ロジックの大半がSQLの中に記述されてしまうため、Javaで組んだにもかかわらず、中心となっているのがJavaではなくSQLとなってしまうのです。こうしたSQL文がソースコードの中に散在するのをオブジェクト指向の人は嫌います。
そこでオブジェクト指向では、SQLを扱うクラスを限定したり、ORマッピングツールを用いることで、ソースコード中から極力SQLを排除しようとするのです。
オブジェクト指向でリレーショナルデータベースをストレージとして用いている場合、オブジェクトの内容をデータベースの項目にマッピングする必要があります。これをORマッピングといいます。
リレーショナルデータベースには、リレーショナルデータベースに適した形で、テーブルそしてカラムを生成します。データ構造は、オブジェクトとテーブルとで一致することもありますが、しばしば細かいところで不一致を起こす場合があります。これをインピーダンスミスマッチといいます。
これは特にデータベースを専門に扱うデータモデラーとオブジェクト指向を専門に扱うオブジェクトモデラーが一緒になった場合、不一致が起こりえます。
ただ、多くの場合、データをきちんと分析して正規化している限り、データモデルとオブジェクトモデルは一致することが多いです。少なくとも概念レベルでは一致します。
ではどういうところで不一致が発生するのでしょうか。
データベースではしばしば正規化を崩すことがあります。概念設計、論理設計レベルではデータ構造を明らかにする上で正規化を行いますが、物理設計の段になって性能上の問題で検索時のテーブル結合を少なくするため、正規化を崩すことがあります。これは全く物理上の制約からくる問題なので、概念上必然性のないことで、この点でクラス図との差が出てくる場合があります。
また、全く正規化されていない、リレーショナルではない、レガシーなデータベースを使用している場合、この不一致は大きくなります。つまりすでにデータベースが存在していて、それにあわせてプログラミングをしなければならないようなケースでは、ミスマッチの問題は大きくなります。
オブジェクト指向では、人によりますが、何でもオブジェクトにしてしまう場合があります。例えば男性か女性かでデータベースでは一つカラムを追加して、0か1で判定するなどしますが、オブジェクト指向ではこれもオブジェクトにして、Personクラスにしてしまう場合があります。データベースでは多くの属性が紐づく場合を除いてこのレベルではいちいち男女マスターなどを作ったりはしません。
あるいは例えばお金を表すのに、データベースでは金額と通貨コード二つのカラムを作るのに対して、オブジェクト指向では専用にMoneyクラスを作りその中のメンバーにこの二つを加えます。
またオブジェクト指向では、Personインターフェースをつくり、その実装クラスとしてMaleクラスとFemaleクラス作ることもできます。こうすることでポリモーフィズムを使い、男性の場合と女性の場合の処理を分けることができます。
この点は、オブジェクト指向では、データに加えて振る舞いを記述できるという違いから出てきたものです。もし振る舞いを考慮しなければ、オブジェクトモデラーもわざわざ何でもクラスにしてしまうということはありません。
この埋込エンティティの問題は、ORマッピングを困難にしている大きな要因です。
データベース設計でも、論理設計の段階ではサブタイプといって親テーブルの属性を継承する設計方法をとることがあります。しかし実装段階では、その構造を崩して一つのテーブルにまとめることがあります。その方が都合がいいからです。あるいは親タイプの内容をすべてサブタイプの方に入れてしまう方法も採られます。
しかしオブジェクト指向側で、一つにまとめずクラスを継承する形をとっていると、構造のミスマッチが生じます。
データベースでは、テーブルとテーブル間を関連付けるには、両テーブルに同じ値を入れて、それを参照制約という制約を作ることで行います。テーブルそれ自体で、関連するテーブルを指し示すことはできません。
それに対してオブジェクトでは、直接関連するオブジェクトに参照を張ることができます。
テーブルでは、関連を示すのに相手のIDを必要としますが、オブジェクトでは直接相手のオブジェクトをセットします。
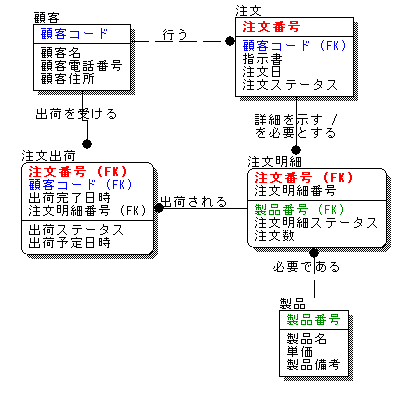
create table company (comid integer, comname varchar2(100));
create table employee (empid integer, empname varchar2(100), comid integer references on company(comid));
Company
001 ABC商社
002 BBD商社
Employee
001 山田 001
002 佐藤 001
003 小林 002
class Company {
String companyname;
}
class Employee {
Company company;
String employeename;
}
データ中心指向的にクラスを作ると、以下のようになります。
class Employee {
String companyID;
String employeeID;
String employeename;
}
ただリレーショナルデータベースを使ってORマッピングする場合、現実的には、IDが必要なので、以下のように、
class Employee {
Company company;
String employeeID;
String employeename;
}
となる場合があります。
また、オブジェクト指向では、双方向に関連を持たせることがあります。上記の例だとEmpolyeeからCompanyに対して参照はありますが、CompanyからEmployeeの参照がなく、CompanyがEmployeeを所有しているにもかかわらず、知ることができません。この場合以下のようにして、Employeeのリストを保持します。
class Company {
String companyname;
List<Employee> employees;
}
また、データモデルでは、関連テーブルというのが登場します。例えば生徒とセミナーがあり、多対多で対応する場合、データベースの物理モデルではテーブル間の多対多を表現する方法はないので、関連テーブルを用いて、そこに生徒IDとセミナーIDのカラムを作って、関連を表現します。
ところがオブジェクトでは、関連オブジェクトを作らなくても、多対多の関連を表現できます。
class Student {
String name;
List<Seminar> seminars;
}
class Seminar {
String name;
List<Student> students;
}
以上見てきたとおり、オブジェクトモデルでは、関連するオブジェクトはすでに結合された状態にあります。そのため、例えば会社名を取り出したい場合、EmployeeオブジェクトからメンバーのCompanyオブジェクトを取り出して、そして会社名を取り出せばいいのです。データモデルでは、結合しないと関連するオブジェクトを表示することはできません。
ただし、これはオブジェクトが生成された後の話であって、どうやってそのオブジェクトを生成するかはまた別問題です。後で述べますが、データベースからこの構造のオブジェクト生成するのは実際簡単ではありません。
しばしばオブジェクトは木構造で、テーブルは表構造であるため、相性が悪いとの記述を見ます。テーブルが表構造というのは、各インスタンスをリスト化したからそうなったのであって、オブジェクトでもリスト表示すれば表になります。そうすると、テーブルの一行はインスタンスの属性を列挙したものでオブジェクトと一致します。テーブルを関連付ければ、階層構造、木構造になります。
またデータベースは構造が固定化され、それに比べてオブジェクトの方は柔軟であるという人がいますが、オブジェクトも構造を変更すれば、再度コンパイルが必要になります。しばしば、オブジェクトと親和性の高いXMLが取り上げられて、RDBに比べて、XMLの方は不定形であるとの主張も聞きます。とはいっても、定型でなければプログラムは処理できないので、結局XMLの構造が変わるたびにアプリケーションも変更が必要になります。
ただ、表示の場合を考えると、テーブルは表での表示が適しており、XMLはすでに結合した形で表示できる、という点で表構造と木構造ということはできます。テーブルを木構造で表示するにはテーブル間の結合が必要になり、オブジェクトやXMLである要素のみ一覧で表示しようとすると抽出作業が必要になります。
以上、ミスマッチについてあげてきましたが、以上の点に引っかからなければデータ構造の不一致はありません。実際、私の周りでは、問題となっているケースはほとんどなく、クラス設計とDB設計は一致しているというプロジェクトも少なくありません。
ミスマッチが露骨なプロジェクトに残念ながら遭遇したことがないのですが、どうもORマッピングを問題にする方々は、インピーダンスミスマッチを過大に取り上げすぎるように見えます。
オブジェクト・リレーショナル・インピーダンス・ミスマッチ(訳文)
オブジェクト・リレーショナル・インピーダンス・ミスマッチ(原文)
オブジェクト指向を用いると生産性が高まるとの期待から、あらゆるアプリケーションに対してオブジェクト指向を適用しようとする傾向があります。しかし、私論では、オブジェクト指向は業務アプリケーションには向かないと考えています。
業務アプリケーションとは、会社の業務である、受発注、会計、在庫管理、人事、顧客管理などのシステムのことで、データ自体が重要な意味を持っています。このようなアプリケーションの場合、DBが比類なく重要であり、DB設計を見れば、どんなアプリケーションなのか粗方見当がつきます。
このアプリケーションに、オブジェクト指向を適用するのは問題があります。
オブジェクト指向のメリットは、カプセル化、すなわちデータと処理が一体になっているところにあります。ところが、業務アプリケーションが対象とするデータ、エンティティは情報としての意味があるだけで処理は必要ありません。ここが多くの人が勘違いしている点です。
例えば顧客を表すクラスとして、Personクラスがあったとしましょう。Personクラスに必要な処理とは何でしょうか。人だから、歩く、食べる、考える、仕事する、などのメソッドが実装できるでしょうか。ほとんど意味はありません。
多くのオブジェクト指向の教科書が出すたとえが役立たないのはこの点です。Person単体では意味の持たせようがありません。setter, getterがあるといわれるかもしれませんが、それはPersonに実装する「機能」ではありません。もちろんsetterやgetterで整形したりできるメリットはありますが、publicのgetterやsetterの単純な実装であるなら構造体となんら変わりません。
対照的な例として、例えば、Stringクラスを見てみましょう。これはメンバーに文字列を持ち、その文字列に対して、検索や部分的な取り出し、比較などのメソッドが実装されています。まさにこれは適切なオブジェクト指向の実装です。
また、例えばCalendarクラスを見てみると、これはメンバーに、指定した日時が格納され、それに対してさまざまな処理ができます。
ところが、Personクラスでは、その名前から想像されるような機能は何一つありません。ある本では、従業員クラスがあって、業務を遂行するというメソッドを例として書いていますが、これは全くナンセンスです。
お分かりのように、業務アプリケーションでは、そのエンティティクラスに機能を実装する意味はほとんどありません。構造体を少し便利にすることが可能、というぐらいのものです。
データ自体は現実を反映していますが、オブジェクトというほどには昇格できません。このようなエンティティのクラス図の作成は、正規化されたE-R図とほぼ同様になり、DOAで用いられるデータモデル手法がそのまま適用できます。
・検索・更新メソッドの必要性 −データと振る舞いの分離
また多くのオブジェクト指向の解説書で、ドメインクラスにオブジェクトの検索、登録、更新、削除を実装するメソッドが記述されている例があります。そしてこれこそが必要なメソッドであり、それを記述できるクラス図はER図に勝っているような言い方をします。そして、実際にEJBのエンティティBeanをはじめとするActive Recordパターンではそのような実装をしています。
しかし、私はこれは奇妙に思います。
まず先ほども指摘したとおり、Personエンティティがあった場合、その登録・更新等のメソッドは別に「人」というものに起因するものではなく、他のエンティティでも共通のものです。データベースと同期させるメソッドがそこに実装されているのは、そうするのが便利であったとしても、やはりそのオブジェクトにまつわる機能ではありません。登録・更新メソッドは、データベースと同期しようがしまいが、オブジェクト指向の観点から言えば、コンストラクタやsetterメソッドに過ぎません。
さらに言うと、Personクラス自体に検索や削除のメソッドがあるのは奇妙です。検索はPersonの集合に対して行うものなので、その集合を保持するクラスあるいは別のPersonManagerのようなクラスが行うべきです。クラスとインスタンスを分けて、クラスメソッドとして実装するのも手ですが、デザイン的にあまりよろしくないと思います。
また削除についても、削除自体を行うのはやはりそのオブジェクトの外部です。削除に関係して、終了処理をそのオブジェクトに記述するのはいいことですが、削除自体はそのオブジェクトの外部で行われるものです。
・EJB
EJBの実装にはその点で疑問があります。インスタンスが一レコードを表すと同時に、検索やDBへの変更・削除を実装することになってしまいます。そして結局、DTOやValueObjectを導入するという奇妙な結果になります。
・ORマッピング
HibernateなどのORマッピングフレームワークでは、エンティティクラスと、データベースとの同期を行なうクラス(これはライブラリ化されている)、そしてそれを指示するクラス(DAO[データアクセスオブジェクト])に分離されています。
こうなると、エンティティクラスは、単なるデータを保持するデータオブジェクトの役割でしかなく、アプリケーションの中枢を構成するドメインクラスとしての役割は果たせません。
そして、サービスクラスにしろデータアクセスオブジェクトにしろ、データはエンティティクラスとして別に分離されているので、メンバー変数を持たない、ステートレスなクラスとして実装されることになります。Javaを使って、ちょっとデザインパターンを使ったフレームワークを使っているという理由だけではオブジェクト指向でプログラミングをしていることにはなりません。
オブジェクト指向の説明で述べたとおり、オブジェクト指向の利点は、ステートフルなことです。オブジェクトは状態をオブジェクト内で保持できるのです。
これは手続き型指向への逆戻りのようにも見えます。データと振る舞いが完全に分離されています。しかしこれは悪いことではありません。というよりも、この方がわかりやすく、また扱いやすいのです。ここはデータ中心指向が、手続き指向に対抗するものとして出てきた経緯を考えると、当然の結末です。データと振る舞いを分離したほうがいいのです。デザインパターンなどの実践でも、エンティティ中心のクラスと処理中心のクラスは分離されます。
結論として、エンティティクラスはほとんどオブジェクト指向のメリットは生かせず、そのため教科書に出てくる現実のもののたとえは全く当てはまらなくなります。エンティティクラスは単なるデータであり、生き物にはなり得ません。エンティティに処理を加える必要はありません。データモデルに重点を置いたデータ中心指向と、クラス図に中心をおいたオブジェクト指向とは全く別ということになります。
もちろんオブジェクト指向バリバリの処理系でもエンティティクラスは出てきます。しかし処理系ではエンティティクラスが中心ではないので別段そこに処理が実装されていなくても問題ありません。UMLの教科書ではわざわざ処理を加えますが、上記の理由から不適切です。
・オブジェクト指向に向いているもの
もし先ほどのPersonクラスが、ゲームアプリケーションの中に登場するとしたら話は異なります。このPersonオブジェクトは、ゲームの中で、歩く、走る、食べる、闘うなどのアクションを持つでしょう。
これはそのアプリケーションの中でPersonという実体が存在し、動作を行う意味を持っているからです。
オブジェクトが何らかの機能の担い手となっている場合、オブジェクト指向を適用しやすくなります。これはGUIアプリケーションや処理中心の制御系のアプリケーションには最適です。GUIを使ったスタンドアローンアプリケーションの場合、オブジェクトが可視化されているので、多くの場合動作が伴います。例えばメールアプリケーションの場合も、メールオブジェクトには送信という動作が伴います。
しかし、業務アプリケーションでのオブジェクトには動作がありません。よって純粋にオブジェクト指向を適用するというふうにはなりません。
よく情報処理試験の解説書には、データ中心指向から発展してオブジェクト指向が出てきたとされるが、これは間違っています。オブジェクト指向もデータ指向もいずれも手続き型(プロセス指向)から出てきています。
もちろん、部分的にオブジェクト指向を使うことはできます。フレームワークの部分や何らかの処理をする部分にはオブジェクト指向を使うことができます。しかし中核になっている部分は、手続き型+データ中心指向です。でも、それでいいのです。
データモデルの本でも、データモデルは現実世界を反映していると説明されていることがあります。これはオブジェクト指向の解説書に説明されていることと同じでしょうか。
全く違います。
また、データモデルの本で、現実世界を反映、という表現は、オブジェクト指向の説明同様誤解を招きます。これはオブジェクト指向、データ中心指向共通の誤解です。まずそれを説明しましょう。
現実世界を模倣してデータモデルを作ったのでは、正しいモデルにはありません。何を現実世界とするかですが、もし物理的世界を考えているのであれば、おそらく間違ったモデルを構築することになるでしょう。発注、受注、履歴、在庫といったものは、現物としては存在しません。発注書や帳簿は単なる紙に過ぎません。仮にペーパーレスで取引をしているところとなると、現実世界に物質としての対応物はないことになります。発注、受注、在庫、履歴は概念、あるいは関係性として存在しています。
在庫は、商品というかたちできちんと対応するものがあると思われるかもしれません。もしゲームを作るのであればそれでよいでしょう。店オブジェクトに、複数の商品オブジェクトが含まれています。客オブジェクトが、店員オブジェクトにお金オブジェクトを渡したとき、店員オブジェクトは、レジオブジェクトにお金オブジェクトを追加し、客オブジェクトに商品オブジェクトを渡すのです。このモデルで管理される情報は何でしょうか。店オブジェクトにある商品オブジェクトの数などになりますが、これは現在何があるかということで、履歴は一切ありません。しかし重要なのは履歴の方です。現実世界には履歴はありません。
レシートや帳簿があるというかもしれません。しかしこれは現実世界としては紙です。「いや、そこにはレジシステムというオブジェクトがある」と言うかもしれません。しかしこれは奇妙です。レジシステムは、データモデルによる設計を経て構築されたものです。それをオブジェクトとして扱うのは奇妙なことです。
「そうではなくて、レシートに書かれている情報を管理するのだ」と言うかもしれません。そうなると、レシートに書かれている、ともすれば冗長な内容をそのままオブジェクトとして持たなければならなくなります。
「そんな誤解するやついるわけない」とおっしゃるかもしれません。多分私だけかもしれません。そうなると、私一人だけのために無駄な文章を読ませてしまったことをお詫びします。
とりあえず続けますと、以上のことから、システムやデータモデルは、現実世界を模倣したものではない、ということがいえます。
もし、原始的な社会で、複雑なことを考えないで、現在何を持っているかを知っていればいいだけの場合、先ほどもモデルでいいでしょう。もっとも、モデリングする必要もシステムを構築する必要もありませんが。
ところが現実には、税務署に申告する必要もあるでしょうし、商品の引渡しと現金の受領が合致しているか、どんな商品が売れたのか、などを管理する必要があるでしょう。
現実にあるものを列挙するだけでは不足しています。商品情報や店舗情報だけでは何かが足りないのです。最も重要なのはそれらのものの移動の履歴です。取引の記録を管理する必要があるのです。現実世界で扱われている情報を反映することです。何の情報を管理する必要があるのか、これを考えていくのです。
そうするとあくまでも対象は情報になるので、情報それ自体に機能は不要です。商品にテレビがあっても、必要なのはサイズや方式などの属性であって、スイッチを入れる、チャンネルを回す、映像を表示する、といったメソッドは不要です。なので、オブジェクト指向の、現実を反映は業務アプリケーションには当てはまらなくなります。
オブジェクト指向を徹底する場合、データベースの存在を意識しないのが理想です。データベースおよびオブジェクトの扱いについて、データ中心指向とオブジェクト指向では大きな違いがあります。
オブジェクト指向では、データベースは単なる記憶装置に過ぎません。極端な場合、データベースのデータをそのままメモリにオブジェクトとして取り込み、メモリ上ですべてを実現します。オブジェクト指向の人にとってはエンティティクラスがドメインの中心であり、DBは永続ストアで陰に隠れています。
データ中心指向では、データベースを中心に考え、SQLで実現できるロジックはすべてSQLで実現します。そのため、プログラムで使用するオブジェクトは、ユーザインターフェースとの受け渡し、処理用のテンポラリとして使ったり、キャッシュとして使い、あくまでも補助的な位置づけになります。データ中心指向の人にとってエンティティはDBそのものであり、エンティティクラスを作る必要はほとんどありません。
ここでは、端的な例として、メモリ上で業務アプリケーションを構成することを考えてみましょう。オブジェクトを生成・更新したときに、オブジェクトのままファイルに出力します。
簡易なアプリケーションの場合、これで事足ります。実際作ってみましたが、非常に便利です。オブジェクトのまま扱えるので、ORマッピングをする必要がありません。
しかし、ここにはいくつかの問題点があります。
・検索およびそのためのインデックスを都度組む必要がある
・参照先のオブジェクトも都度生成(遅延ロードなどのメカニズムが必要)
・排他制御、トランザクションのメカニズムを組み込む必要(他のプロセスが独自にデータにアクセスすることがないようにする)
・大量のデータに対応できない
メモリを逼迫する。メモリに乗り切らずディスクに退避する場合ディスクアクセスが発生する。メモリ上で大量のデータや同時ユーザアクセスを受け付けるのには負荷が大きすぎる。
以上のような問題をあげることができます。
特にメモリ上のオブジェクトを共有するようになると話が厄介になってきます。読み取り専用にしたり、あるいは更新用の一時的なオブジェクトを別個に用意したりといった必要が出てくるでしょう。ダーティリードを防ぐために、別オブジェクトを用意して、そこで更新しておいて参照を切り替えるなどの工夫が必要です。しかし、そのオブジェクトへの参照が多いとそのすべてを同時に書き換える必要が出てきます。データの一元管理にはさまざまな問題が付きまといます。
エンティティをすべてメモリで持つメリットとしては、データベースのような結合処理を行う必要がないことがあげられます。無意味なIDを持って関連させる必要がなくなります。
その反面、検索や更新・削除、同時アクセス等、解決すべき問題は多くなります。このような処理を専門に扱い、それらの機能を十分考慮して実装したのがDBMSです。DBMSはこれらのことが十分に考慮された巨大なシステムとなっており、十分な安定性・信頼性があります。そしてそのアクセスにシンプルな言語であるSQLを用います。
もし、対象となるアプリケーションが、
1. マルチアクセス
2. データ中心
のどちらかであるならいいと思います。例えば、メーラーなどのアプリケーションもデータ中心ですが、大きな違いはスタンドアロンでメールデータにアクセスするのはシングルユーザという点です。この場合、排他制御やトランザクションは不要になります。
しかし、両方を満たす場合は、通常の手段では、純粋なオブジェクト指向は不可能です。オブジェクトデータベースを使うか、ORマッピングツールを使って擬似的に行うことによってこの問題をクリアすることができます。ただし、依然、先ほど述べたとおりエンティティには機能は不要なのでやはり純粋なオブジェクト指向とはいえません。
・定型化 vs 非定型化 --参照があるかないか
データアクセスという点で、オブジェクトとリレーショナルデータとには大きな違いがあります。データの登録・更新・削除といった点では大きな違いはないのですが、データの検索・分析となると、定型化および一般化されているデータベースの方が遥かに有利で、データ量が多くなればなるほど、優劣の差が出てきます。
オブジェクト指向では、オブジェクトへの参照を持っていないと、オブジェクトを持ってくることができませんん。同じクラスのインスタンスすべての中から検索するのは、それらすべてがリストに格納されているなどしないと、難しいことです。一方、データベースはグローバル変数と同じでいつでもアクセスできます。クラスに対応しているテーブルの中を検索すれば、すべてのインスタンスを検索対象にすることができます。オブジェクト指向ですべてを処理しようとする場合、オブジェクトを生成するときにそのオブジェクトに対する参照を誰が持っているかについて注意を払う必要があります。
データベースでは、どのようなテーブルを設計仕様とも、同様のSQLで検索処理ができますが、オブジェクトでは、オブジェクトごとに処理ロジックを作るか、形式を合わせることで、処理を共有化する必要があります。
そもそも、プロセス指向(手続き型)からデータ中心指向へなぜ移行したのかを考えると、まずプロセス指向では、データはプロセスの中にありました。そうすると、データが散在しするため、まずデータを外出しにして一元管理します。さらに正規化の手順を踏んで、冗長性をなくし、データの不整合をなくすようにしました。データへのアクセスは標準化されたSQLを用います。
さらに、DB側で排他制御やトランザクション管理機能、制約を持たせることで、それまでプロセス側で行っていたことの多くをDBMS側に委譲できるようになりました。例えば一意制約をDB側で保証してくれるため、プログラム側ではそれほど神経質にならなくて済むようになります。そして絞込みや結合、ソート、集計などをSQLだけで実現するようにすることで、さらにプロセス側の負担を減らすことができました。
このようにして、プロセス指向からデータ指向への移行において、データの重要性を高め、データに関係するロジックの多くを、DBMSとSQLで実現できるようになりました。
これと同様のことは、プロセス指向からオブジェクト指向への移行においても起きました。それは、同じようにデータを重視し、データとそれに関係するロジックを一まとめにして扱うオブジェクトという形で実現されたのです。この部分の発想は、データ中心指向もオブジェクト指向も共通しているものがあります。なので、設計段階でどちらもドメイン分析をして、データ中心指向ではデータモデル、オブジェクト指向ではクラス図を作成します。
これでいい方向に向かったはずでしたが、問題は、データ中心指向で設計された業務アプリケーションに対して、オブジェクト指向言語を適用することで起きました。これを解決すべく、ORマッピングということが持てはやされるようになりました。
実際のアプリケーションを組む際に、ドメインクラスをどのように構成するか、そしてSQL文をどう扱うかというのが問題になってきます。
ドメインクラスの構成の仕方ですが、
・SQLとプログラムロジック
プログラムで実装しようとした検索や統計処理などほとんどのことは、SQLでできてしまいます。そのためプログラムでのロジック層やサービス層は単にSQLを発行するだけで実際のロジックは必要なくなり、単にコントローラの役割でしかなくなります。
SQLでは表示フォーマットも指定できますし、ストアドプロシージャを使えばDB上でほとんどのロジックを組めてしまいます。ストアドプロシージャはプログラミング言語なので、ロジックが単にDB内にシフトしただけですが。
そうなるとアプリケーションの構造としては、オブジェクト指向で考える、UI - ロジック - エンティティの構造ではなく、UI - コントローラ - DBという形になり、エンティティクラスも不要になります。実際、シンプルなアプリケーションの場合、エンティティクラスを作る必要はまったくありません。
Webアプリケーションの場合、リクエストを受け取ったら、そこからパラメータを取り出し、コントローラがSQLをセットし、結果セットをそのままJSPに転送し、JSPで適当にViewにセットする形で十分です。
もう少し凝ると、入力を一式をデータオブジェクトにセットし、DBにアップデートする内容をテーブル単位のエンティティクラスに格納し、特定のテーブルにSQLを発行する部分をコントローラから分離してDAOとして、またSQLで補えない部分をビジネスロジック・クラスとして実装するようにします。複雑な仕様になるとどうしてもSQLだけではできない部分が出てくるからです。さらに結果セットをViewにそのまま渡すのではなく、表示用のViewオブジェクトにセットするようにします。
とはいえ、依然中心はSQLにあります。オブジェクト指向派の人でSQLが嫌いな人がいますが、しばしばSQLでできることまでロジックで実装しようとします。SQLは構造化されたシンプルな言語ですが、Javaとは構造が異なるし、構文エラーがあってもコンパイラは指摘してくれないので、それが嫌われる点です。
その一方で、なぜかXMLはオブジェクト指向と親和性が高いと考えて好んでXMLを使用するのは理解できません。
ソースコードに記載するロジックとSQL文の関係については、
というパターンがあります。これについての詳細は、ドメインロジックとSQLを参考にしてください。
またSQL文の記述方法については、
というパターンが考えられます。
ソース中に直接書くというのは、ソースが汚くなるパターンですが、何のSQLが発行されているのかすぐにわかるというメリットがあります。
2はSQLをファイルに外出しし、必要であれば共有化します。ソースコードとSQL文が分離されてきれいになりますが、何のSQLが発行されているかファイルを開いてたどらないとわかりません。また検索条件の組み立てなど、ダイナミックにSQLを生成しにくいという問題があります。
いずれの場合であっても、SQLを発行するレイヤーは限定していた方が問題があったときの調査が楽です。これがDAOを作る意味です。そしてテーブルごとあるいは業務ごとに分類します。そうするとデータへのアクセスを共有化でき、修正箇所を限定することができるようになります。
とはいっても、微妙にSQL文が違うようになると、類似したアクセスメソッドをたくさん作るか、条件分岐を多用したソースコードになり、きれいにはいかなくなります。そうすると今度はSQLを組み立てる専用のメソッドを作り、さらにそれを汎用化してORマッピングツールの登場となります。
後者になるほど、どのようなSQLが発行されているか、ソースを追っただけではわかりにくくなります。データ中心指向の人にとってはつらいことです。一方オブジェクト指向の人にとっては、SQLを排除できるので喜ばしいことでしょう。
実装のパターンについては、こちらのサイトも参考になります。
今だからデータ・アクセスを真剣に考える
もしデータ中心的な発想でJavaを使ってアプリケーションを組むとなると、先ほど述べたようなオブジェクト指向的な形にはならず、エンティティクラスはあくまでもデータを一時的に保持するオブジェクトに過ぎなくなってしまいます。本来オブジェクト指向であるなら、エンティティクラスにメソッドを実装し、最初のクラス分析で書いたようなリレーションを持つべきですが、各エンティティクラスは関連を持ちません。単にテーブルのデータをそのまま持ってくるだけです。
というのは、プログラムの中でも参照先のIDさえあればよく、せいぜい名前さえあればよい場合が多いからです。
例えば、Employeeの表示や更新を行なうアプリケーションを考えて見ましょう。表示の際に、所属会社名を表示する必要があるとき、そのデータを保持するクラスは以下のようになります。
class Employee {
String empid;
String empname;
String companyname;
}
次に更新画面でどうなるかというと、EmployeeのIDが必要であり、またもし会社を変更できるようにするとなると、CompanyIDも必要になります。
class Employee {
String empid;
String empname;
String companyid;
String companyname;
}
(あるいはcompanyidだけを持たせて、別のクラスに会社のIDと名前の対応表を持たせるような形式も考えられます)。
いずれの場合も、Companyクラスの存在を必要としていません。本来のオブジェクト指向的な発想からすれば、このようなドメインクラスの構成はNGです。しかし、実際には業務アプリケーションを組む場合、このような形になってしまうことがあります。理由は先ほど述べたとおりで、完全なオブジェクト指向に沿ったドメインクラスを作るのは難しいからです。
そしてデータへのアクセスは分離されます。DAO(データアクセスオブジェクト)とエンティティクラスに分けられます。
EntityBeanは、業務アプリケーションにおける、ドメインクラスとして考慮されたものです。これによって、オブジェクト指向でプログラミングができると期待されたものです。
public class UserBean implements EntityBean {
public String userId;
public String type;
public String ejbCreate(String userId, String type)
throws CreateException {
this.userId = userId;
this.type = type;
return null;
}
....
}
EntityBeanには性能や煩雑さの問題が取りざたされ、ORマッピングツールにその座を明け渡そうとしていますが、ここではその問題には触れず、構造上の問題に絞って検討します。
初めのうちは、データとロジックの一体化というオブジェクト指向の理念から、EntityBean内にロジックを組むことがありました。しかし、そうするとクラスが肥大化してしまうので、EntityBean内にはデータにアクセスするロジックのみで、データを処理するロジックは分離し、別のレイヤー、ロジック層で処理するようになりました。
またEJBの特性で、EntityBeanの一つのgetter、setterメソッドを呼び出すのにもネットワークを介したアクセスとなり、性能上の問題から、ValueObjectあるいはDataTransferObject(DTO)といったオブジェクトに必要なデータを詰め込んで、アクセスを一回で済ます実践が推奨されるようになりました。
ORマッピングという場合通常、オブジェクトからリレーショナルデータベースへのマッピングを意味します。オブジェクトをツールに渡せば勝手にデータベースへ格納してくれます。
これとは逆に、データを取得する際、データベースから取得したデータをオブジェクトに格納するのがROマッピングです。
ORマッピングツールでは通常この両方を兼ね備えていますが、プロジェクトによっては、ROマッピングだけで十分で、ORマッピングは手動で行うという場合があります。
このROのツールとして適しているのは、jakartaプロジェクトのDbUtilです。これは通常のDB接続をラップしただけの簡素なつくりで、データベースへのアクセスを容易にしてくれます。SQLはデータの格納にしろ取得にしろ手動で組み立て、取得の場合にオブジェクトに格納して返すことができます。
ORマッピングツールには、Hibernate, iBatis, Torque, TopLink, S2Daoその他いろいろなプロダクトが商用あるいはオープンソースとして出されています。
EntityBeanに代わるツールとして注目を集めています。アプリケーションサーバの中でしか動作しないEntityBeanと違い、POJO(Plain Java Object)が中心になっていてアプリケーションサーバの起動なしに動作させることができ、軽量、簡易なツールとして注目を集めています。
ドメインクラスには、EntityBeanと違い、データアクセスロジックは一切記述しません。また単なるデータモデル用のクラスとして、ロジックもほとんど記載しない場合が多いです。
これについては私自身Cacheしか知らないのですが、アクセスの仕方はORマッピングツールのインターフェースに似ています。トランザクションや遅延ローディングについても同じです。ただORマッピングツールがその内部でいちいちSQLを組み立ててデータベースにアクセスするのに対して、Cacheではダイレクトにアクセスできるところが違います。オブジェクト指向でプログラミングして、性能を問題にするならオブジェクト指向データベースを使った方がいいと思います。
データベースを使いこなしている人に聞くと、ORマッピングツールは使いたくないようです。SQLの知識が十分にあるのに余計なことを覚えなければならないし、今まで発行されているSQLをきちんと把握してチューニングしてきたのに、ツールが勝手に変なSQLを発行するのは困る、という理由のようです。
先ほどメモリ中心のアプリケーションの話をしましたが、そこで問題になっていることはここでも問題になります。なので十分にオブジェクト指向でデータを使い回すというわけにはいきません。
・クエリーには結局SQLが必要
ORマッピングツールが解決してくれるのは、IDや単純な検索条件による検索、複数テーブルの結合、作成・更新・削除といったもので、複雑な検索条件になると、やはりSQLの知識が必要になります。オブジェクト指向データベースのCacheでも複雑な検索条件の場合はSQLを使います。エンティティを探し出すにはSQLがやはり便利です。JPAでは、SQLに似たJPQLという言語を規定しています。一種のSQLの方言といえます。ただその言語の中でオブジェクト指向っぽい記述ができ、結合に関する部分については、SQLよりも簡潔に記述できます。
とはいえ、Case文、関数、副問い合わせ、Unionの使用などになってくると、やはりSQLを直で投げるのがいいでしょう。JPQLはかなり対応しているため、それで記述はできるかもしれませんが、こうなってくるとSQLで正直に書いた方がいいのではと思います。ただ、複雑なSQLを書くとやはりロジックが分かりにくくなるため、性能を気にしないのであれば、簡単なSQLを複数回投げて、データを取得する方がいいでしょう。一番いい解決方法はストアド・プロシージャの中でロジックを組むことです。これであれば分かりやすいロジックでしかもパフォーマンスも複雑な単文SQLよりもよくなります。
・BulkUpdateにはSQLが必要
DBからデータを削除する場合、SQLであればdelete一回で削除できます。ORマッピングツールでは、一度データを特定してから削除処理を行うので、一度selectを行ってエンティティを取り出してから、deleteを実行できます。更新についても同じで、一度取り出してから行います。
大量のデータに対して更新や削除を行う場合、特にこれが問題になります。結局こういうケースでは直接SQLを発行することになります。
・インピーダンスミスマッチのため?
既存のデータベースを使う場合は仕方がないとしても、新たにアプリケーションを構築する場合は、問題を避けるために、できる限り、ドメインモデルとデータモデルを一致させます。しかしそうするとインピーダンスミスマッチがあるからORマッピングツールを使うという理由がなくなってしまいます。
・キャッシュの共有について
個々のスレッドがデータベースにアクセスした場合、それらのデータは同一のものであったとしてもそれぞれが持つことになり、あまり効率的ではありません。メモリで展開する場合、共有しているのが理想ですが、ORマッピングツールを使っても、やはりトランザクションの問題等もあって結局は個別に持つことになります。
・余計なデータも持ってくる
トランザクションテーブルには多くのマスタテーブルへの外部参照が入っている場合がある。トランザクションテーブルにはマスターのIDしか入れないのが普通です。その内容を一覧表示したい場合、必要なのはマスターテーブルのNAME列のみですが、ORマッピングツールを使うと通常はマスターテーブルの行データすべてを持ってきてしまいます。ただここは回避する方法もありますが。
・エンティティをViewでは使えない
エンティティをデータベースから持ってくるとき、関連するエンティティをすべて持ってくるのは無駄なので、最初は参照先をデータベースから持ってこないで、後でアクセスしたときに持ってくるようにすることがあります(Lazy Loading)。
ただこれは、エンティティはORマッピングツールで管理されている間だけ、その参照先のデータを取ってくることができます。もし管理下から外れた場合は、アクセスした際にエラーとなります。
これを防ぐには最初から関連エンティティをもってくるか(Eager Loading)、もしくはずっとORマッピングツールの管理下に置くかです(Open Session In View)。いずれも問題があり、後者はプレゼンテーション層からデータベースへアクセスすることになり、レイヤーを分けている意味が薄れます。
そうすると、データアクセス層でのみエンティティを扱い、Viewに渡すときは、必要なデータを揃えて渡すことにします。その際にDTOを使うとすると、エンティティクラスを使っている意味はほとんどないと思います。エンティティクラスの利点は、参照先に簡単にアクセスできることです。それが欲しいのはView層だと思いますが、DTOに詰め替えたのでは、最初から関連先のNAME列を引っ張ってくるようなSQLを書いた方がいいと思います。
エンティティクラスをViewまで引き回す方法もありますが、その場合、データアクセス層で参照先に一度アクセスする必要があります。これもナンセンスです。View層とデータアクセス層でソースが重複することになります。
また管理下から外れた(detached)エンティティは、データを変更してもそのままではデータベースに反映されません。再度マージする手続きが必要となります。これにはこれでいろいろ問題があるようです。
・特殊な仕組みを仕込んでいる場合
例えば以下のように不正更新を防ぐような仕組みをSQLに持たせている場合、通常の簡単な使い方ではうまくいきません。処理の仕方を変える必要があります。
update XXX set YYY=? where XXID=? and USERID=? and DELFLG=0
以上の問題を念頭に置いておく必要があるでしょう。昔はJavaはオーバーヘッドが大きく使い物にならないと言われたりもしましたが、今はパフォーマンスの問題もかなり解決され、特に性能を問題にするアプリケーションでなければ、できるだけオブジェクト指向でわかりやすく、再利用性があるように書くのがよいとされています。
それと同じように、ORマッピングツールも現在は非効率的で分かりづらい部分もあるのですが、将来的にマシンのスペックも上がり、冗長なSQLが発行されても性能的に問題がなくなり、SQLを完全にラップしてSQLを意識しなくて済むようになれば、それがスタンダードの地位を確立するようになるのでしょう。