Olive+ R19で追加になった、スクリプト言語のgeturl命令を使って、Webからデータをダウンロードして、スクリプトで処理するサンプルを作ってみたいと思います。
今回サンプルとして取り上げるのは、天気予報の表示です。
基本形が理解できたら、後はスクリプトでどうにでも変更(対策)できますし、応用も利きますので、是非、参考にしてみてください。
Webからデータ(HTML)をダウンロードして、そこから気象情報を取り出しますので、まずは、対象のWebページを決めなければなりません。ここでは、作者がいつも参照している、Yahoo!(Japan)の天気予報サイトを使いたいと思います。
まず、メインページは、皆さんがお使いの検索サイトから、「Yahoo Japan」などと入力して、見つけてください。
メインページを開いたら、「天気・災害」などとなっているメニュー項目に進み、天気を調べたい地域を選択しながら、どんどん詳細な地域を絞り込んで行ってください。ここでは、作者が昔住んでいた伊丹市の天気を例にとりたいと思いますので、「大阪」→「神戸」と、近い地名を選択していきます。
ここまで選択してくると、地図が消えて、地名を選択できなくなりました。ページを少し下の方に移動してみると、「ピンポイント天気」という欄が見つかります。この一覧の中に、ありました「伊丹市」、これを選択します。
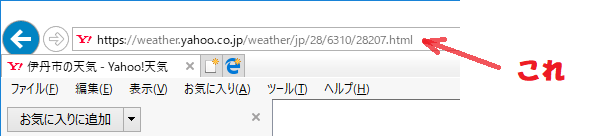
このページのURLをメモ(コピー)しておきます。IEだと、下図のような感じです。
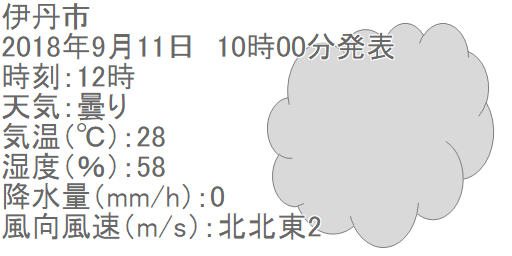
このページには、本日の伊丹市の天気予報(過ぎた時間は過去の「予報」だそうです。実績ではないのね……)が、3時間毎に区切られて表示されています。
Olive+ R19で追加したgeturl命令を使います。この命令を実行すると、インターネットにHTTP要求を出しますので、ファイヤウォールなどによってブロックされないように設定してください。
geturl <url>, <file> ;
geturl命令は、指定したURL<url>へHTTPリクエスト(GET)を出し、レスポンスとしてのWebデータを受け取り、ファイル<file>へ出力します。具体的な使い方は、以下の様になります(さっきメモしたURLを使用します)。
geturl "https://weather.yahoo.co.jp/weather/jp/28/6310/28207.html", "weather.html";
今回ダウンロードするのはHTMLですが、JPEGや実行ファイル(EXE等)、その他ファイルであっても、URLが正しければダウンロードすることが可能です。
実行して取り込んだHTMLファイルをテキストエディタで開いてみます。
今どきのホームページは、大体そうみたいですが、文字セットがUTF-8というコードになっています。今回のページもUTF-8でした。しかし、Olive+はUTF-8のテキストファイルを取り扱うことができません。シフトJIS(S-JIS)ベースのアプリケーションなので……。
せっかくダウンロードできても、処理できないの?
ご安心ください。ちゃんと、テキストファイルの文字セットをS-JISに変換する命令も用意してあります。
ftxtcnv <source>, <destination>[, <option>...] ;
<option>は、出力先の文字セットなどを指定するのに使用しますが、デフォルトで出力先がS-JIS&CR+LF (Windowsの改行コード)となっていますので、今回は指定しなくて(デフォルトのままで)OKです。後は、入力ファイル名<source>と、出力先ファイル名<destination>を指定するだけです。
出力先が既に存在していると、上書きしてしまいますので、ご注意ください。
ftxtcnv "weather.html", "weather_sjis.html";
これで、Olive+のファイル入出力命令で、テキストデータとして読み込んで処理することが可能になりました。
まあ、これが一番大変。真面目に突き詰めて行くと、まさに、「Webブラウザ(レンダラ)を作ってやるぜ!」的なところまで到達してしまうでしょう。それは今回の目的とは異なりますので、もっと簡易的に解析して、必要な情報だけを抜き出せたら終了、とします。
まず、ブラウザで表示されたページとHTMLを見比べて、必要な情報がどこにあるのか?探していきます。必要な情報は以下の通り。
ダウンロードしたHTMLをテキストエディタで開いて、地名である、今回の例では「伊丹市」をテキストサーチしてみます。さすがに、「伊丹市の天気予報」ページを開いているだけあって、色々なところに「伊丹市」という文字列が含まれていましたが、<title>タグに記載された文字列を捕まえるのが良さそうです。
fgetl fin, lbuf;
var ipos;
index ipos=$(lbuf), "<title>";
fgetl命令でファイル("weather_sjis.html")からテキストデータで1行分(改行コードまで)をマクロlbufに取り込みます。ファイルfinは、あらかじめfopen命令を使って読み込みモード("r")で開いておきます。
index命令で、lbuf内に"<title>"という文字列を探します。見つかれば、その文字位置(1〜)が変数iposにセットされます。見つからなかったときは、ipos=0です。
macro w_place;
if (ipos>0)
{
mlet w_place=$(lbuf);
psub ".*<title>(.*)の天気.*", "\1", w_place;
}
ipos>0("<title>"が見つかった)の時、マクロw_placeにlbufの文字列をコピーして、psub命令で".*<title>(.*)の天気.*"というパタンを探します。パタンについては、正規表現に似た文字列検索エンジンの書式ですので、マニュアルをご覧ください。このpsub命令では、".*<title>(.*)の天気.*"という文字列を探して、"(.*)"に相当する部分だけをw_placeに残せ、という意味になっています。"(.*)"の部分には、「伊丹市」という地名が記載されているので、w_place="伊丹市"となります。
日時も同様ですが、地名のようにちょうど良いタグがありませんでした。下のような感じ。
<p class="yjSt yjw_note_h2">
2018年9月10日 22時00分発表</p>
<p>タグの内側ではありますが、改行されているため、行単位の読み込みだとうまく見つけられません。そこで、ちょっと無理やりですが、以下のようにひっかけてみます。
pindex ipos=$(lbuf), "[0-9][0-9][0-9][0-9]年[0-9]+月[0-9]+日 [0-9]+時[0-9]+分発表";
ここから日時情報を取り込みます。
正規表現に似た、検索パタンを使う場合のpindex命令と、単なる文字列を検索するindex命令が混在していますので、ご注意ください。
ようやくメインディッシュですが、さすがにこれが一番厄介でした。3時間毎の天気予報が表になっていますので、HTMLを見ると、<table>タグの中に、<tr>と<td>で行と列が記述されています。しかも厄介なことに、<td>〜</td>が一行に記述されておらず、途中に改行が入っていたり、かと思えば1行の中に複数の<td>〜</td>ペアが記述されていたり、中々手強い。ただ、結合された行や列が無いので、(<tr>タグを無視して、)<td>〜</td>ペア毎に抜き出し、すべての要素を配列に取り込んでしまえば、あとはN(=9列だと後でわかります)要素飛びにアクセスすれば、必要なデータを抜き出せることがわかりました。
まず、以下の手続きで、現在読み込んだ行データlbufの中に"<td>"が含まれていて、かつ"</td>"が含まれていなかった場合、"</td>"が見つかるまで、次の行を読み込みながら、lbufに追加していくことにより、lbuf内に<td>〜</td>タグが含まれるようにします。
procedure get_td
{
// <td>〜</td>ペアを取り込む
pindex ipos=$(lbuf),"<td[ >]";
if (ipos>0)
{
macro buf;
index ipos=$(lbuf),"</td>";
while (ipos<=0)
{
fgetl fin,buf;
strcat lbuf,$(buf);
// 継続
index ipos=$(buf),"</td>";
}
}
}
手続きget_tdを実行して戻って来た時には、行データlbufには<td>〜</td>が含まれていますので、以下の様な文字検索・置換パタンを使って、タグを消去し、データだけを取り出します。
fgetl fin,lbuf;
get_td;
macro dat;
mlet dat=$(lbuf);
psub "</td>.*","</td>",dat; // </td>以降の文字列を消去
pgsub "<[^>]+>","",dat; // タグを消す
psub "^[ \t]+","",dat; // 先頭の空白を消去
psub "[ \t]+$","",dat; // 末尾の空白を消去
// 配列に取り込む
mlet w_data#(idx_w)=$(dat);
idx_w=idx_w + 1;
この処理を"</table>"タグが見つかるまで続けます。表は行タイトル、列タイトルを含めて、9列×6行=54個のデータが有りますので、配列w_dataには0〜53までのデータが格納されています。
9列 : 行タイトル(時刻)/0時/3時/6時/9時/12時/15時/18時/21時
6行 : 時刻(列タイトル)/天気/気温/湿度/降水量/風向風速
二次元配列である天気の表が、一次元配列に収まっていますので、列の数(=9)置きにアクセスすることによって、特定の3時間毎の天気情報を取り出すことができます。
現在時刻を取り出す命令は、date命令とvtime命令がありますが、「今の時間を3時間毎に丸めたい」という用途に対しては、vtime命令が適切です。
vtime <variable>;
変数<variable>に今日の日時を代入する命令です。日時は、1900/01/01の00:00:00を2とする単位[日]の数値です。よって、整数部分は1900/01/01からの経過日数になっており、小数点以下の値は時・分・秒を表しています。
例えば、H時M分S秒の場合、<variable>に設定される数値の小数部分は、((S/60+M)/60+H)/24となります(Hは24時間制)。
現在の3時間毎の時間を知りたいので、1.5時間(=3時間/2)で丸めて(四捨五入?……ではないけど……)、以下のように求めます。
var vtim;
vtime vtim;
vtim=round ((vtim - w_vtim)*24/3);
clip vtim=0,15;
// vtim:0〜7(0=0時から3時間毎に、7=21時まで対応)
// (さらに、vtim=8で翌日0時〜15=翌日21時まで拡張)
1.5時間で丸めているので、一番近い3時間が算出されています。例えば、15:32だと一番近い15時のデータ、11:45だと一番近い12時のデータを表示します。
さらに、ちょうど日付が変わった頃にデータをダウンロードした場合、まだHPの方が、変わった日付に更新されていないケースが考えられますので、天気予報の日時を取り込んだところで、日付をvtime形式に変換してw_vtimに保持しています。
// 日付をvtimeに変換する
macro buf;
mlet buf=$(w_date);
psub ".*([0-9]+)年([0-9]+)月([0-9]+)日.*","\1 \2 \3",buf;
var nn;
field nn=buf;
vtime w_vtim=$(buf1),$(buf2),$(buf3);
これも、パタン検索・置換を使って、年・月・日の数値部分を抜き出し、field命令を使ってスペースで区切られたフィールドに分割、vtime命令で年・月・日を指定して実数日付に変換しています。
天気のデータはw_dataというマクロ配列に格納されています。以下のような感じ。
w_data#(0)〜w_data#(8):時刻/0時/3時/6時/9時/12時/15時/18時/21時
w_data#(9)〜w_data#(17):天気/3時間毎の天気×8個
w_data#(18)〜w_data#(26):気温/3時間毎の気温×8個
:
w_data#(45)〜w_data#(53):風向風速/3時間毎の風向風速×8個
前の節で求めたvtimは0〜7ですので、w_dataの添え字に対応させるために+1して使用します。例えば、時間帯が9時であれば、vtim=3と計算されていますので、+1して4から9置きにw_dataへアクセスすると、以下のようになります。
vtim=vtim + 1;
w_data#(vtim + 0*9) : 9時
w_data#(vtim + 1*9) : 9時の天気
w_data#(vtim + 2*9) : 9時の気温
w_data#(vtim + 3*9) : 9時の湿度
w_data#(vtim + 4*9) : 9時の降水量
w_data#(vtim + 5*9) : 9時の風向風速
これらのマクロを適当にフォーマットしながら、表示すべき情報を生成します。
あくまで、「サンプルスクリプト」ですので、文字情報だけでも十分だったのですが、「晴れ」とか「雨」とか言った情報で、天気の絵記号を背景に設定できるようにしてみました。例えば、「晴れ」だった場合は、以下の如く。

ファイル名が、"pp_weather_<天気>.xpic"というルールに則っている必要があります。執筆時点では「夏」なので、「冬」になって、「雪」の予報が登場した場合とか、現時点で認識している以外の天気が登場した場合は、画像は付きません。あしからず。
別な画像ファイルフォーマットにしたい場合は、スクリプト内の拡張子を変更してください。".xpic"は、Olive+で読み込み/セーブ可能です。
ある程度、HTMLのソースを解析できる能力が必要となりますが、Webからのデータ取得が可能となったことで、様々な応用が考えられます。
「1つのHPだけを見て終わり」なら、Webブラウザで開いて閲覧しても良いですが、最近は広告とか、ページに設定されたスクリプトの動作が遅くて、苛々することがあります。HTMLだけを読み込んで、必要なデータだけを吸い出して表示出来たらそれで事足りるわけです。わざわざブラウザで余計な情報まで表示する必要はありません。
それに、ぐらっと揺れを感じた時は、「震源は?地震の規模は?」と、気になりますよね?HPによって、更新されるスピードが異なっていたりしますので、いくつか情報が表示されるHPを解析しておいて、Olive+のスクリプトを実行したら複数のページを読み込んで、必要な情報を吸い上げて表示できるように準備しておくと、いち早く必要な情報に到達できるでしょう。
面白い(有用な)使い方を考えてみてください。
完成したスクリプトです。
| Olive+スクリプト | PP_WEATHER.zip |
スクリプトの仕様上、お天気画像ファイル名に「晴れ」などの日本語文字を含むため、ZIPでアーカイブしてあります。適切なディレクトリに解凍してご利用ください。
なお、本スクリプトは、執筆時点のYahoo!天気ページを簡易的に解析するスクリプトであり、Yahoo!天気のHTML仕様が変更になった場合、正しく動作しなくなる場合があります。
Arduinoという、MCU(Micro Controller Unit)ボードがあって、比較的簡単に電子工作(DIY)ができる環境を手に入れることができます。Auduinoと気温・湿度センサを使って、「部屋の気温と湿度のログを自動取得する」目的に向かった記録を、「Arduinoを使った電子工作の部屋」でご覧いただけます。
本ページで解説した、Webから気象情報を取得するスクリプトを応用して、気温・湿度データ+その時の気象情報を一括してログに残すまでの記録になっていますので、ご興味のある方はお立ち寄りください。


