JAVA PRESS Vol.13
『IBM と Sun のコラボレーション XMLパーサ Xerces-J活用術』
-Apache XML Project大研究-
入校バージョン
伊賀みどり (http://www003.upp.so-net.ne.jp/midori/midosoft.html)
|
| 前提 |
| はじめに |
私は ほんの少し前まで,XMLはXMLを調査研究する人々だけが好きこのんで扱う
“もの” であるように感じていました.XMLの理念やXML関連技術を用いて実装されるソフトウェアのすばらしさについては
ぼんやりと理解できるのだけれども,現実の開発の中で
実際にXMLを活用する余力・余裕は無いだろうというのが
私の以前のおおざっぱな判断でした.これは
その当時 <2000/06/11 修正: 理解が足りなかったのが主な原因と自覚しました> 私がXMLに対して理解が全く無かった,XMLを扱うことができるライブラリやソフトウェアが身近に無かった <2000/06/11 修正: 高価だと思っていたのは
私の勘違いでした> ことが,この判断結果を より強固なものにしてしまっていたように思えます.(例えば
XMLパーサー ライブラリを ぐりぐり自作するなんて事は
全く思いつかなかったのです) この記事を読まれているみなさまも,少し前までは「XMLは面白そうだけれども実際に使うのはまだ先なのだろうな」と思われていた方が大半なのでは無いでしょうか.
ところが ついほんの最近 XML専門家では無い
一般のソフトウェア開発者の間でも XMLブーム熱が
にわかに高まり出しました.世間のIT雑誌などでも
XMLを利用した具体的な事例が 特集などの形を取って
組まれているのを見かけるようになりました.実は
私も 最近「XMLは 既に “使える”技術なのでは無いか?」と思いはじめ
手を染めだした所なのです.(先に断っておきますが
私はXML専門家ではありません) 堰を切ったような
このXMLブームには理由があります.むろん企業間電子商取引,動的ウェブページ生成,コンテンツと見栄えの分離などの各種の潜在的需要があった上でのことなのですが,その理由とは
等のXMLを利用してソフトウェアを実現するための手段が整ってきた,または入手しやすくなったなどの開発インフラの充実こそとが,つい最近のXMLブームの原動力となっているように思えております.
今回 この記事で取り上げる『Apache XML Project』は,まさに上で述べた
XMLを利用してソフトウェア開発を実現するためのソフトウェア群を提供しようとするものなのです.このプロジェクトには現時点では
下記の6つのサブプロジェクトが含まれています。
むろん それらの中には まだ開発途上のものもありますが,既に製品レベルに到達しているプロダクトもあります.
なお Apacheという冠からウェブサーバ関連かと誤解を受けそうですが,『Apache
XML Project』はウェブサーバとは独立した アパッチ・ソフトウェア財団のプロジェクトの一つなのです.
なお Xerces という XMLパーサーについて,XMLパーサーと来れば
すぐに IBM alphaWorks の XML Parser for Java
や サン・マイクロシステムズ Java API for
XML Parsing を連想される方も多いことでしょう.後で述べますが
Xercesは それら IBM や サン・マイクロシステムズのプロダクトとも
とても深い関係があるのです.
Apache XML Projectについて 歴史も短く 資料もウェブ以外では入手困難な状況でして
うまくご紹介できるのか少し心配です.しかし一方
このプロジェクトは 既存のIBM,サン・マイクロシステムズ,ロータス・デベロップメントなどの既存XML関連プロダクトをスタート地点としてしかもそれらを統合してしまおうとするものでして,今後
XML関連ソフトに多大な影響を与えることは必至なのだと予想しています.そのような背景から、XMLに興味を持っているJava屋さんに紹介したく思い
今回執筆させていただく次第です.
| XMLの基礎的な情報について |
XMLに関して あまりご存じ無い方のために、XMLの基礎的な情報について
簡単に書かせて頂きます。かく言う私も ごく最近まで
XMLには あまり関与してこなかったので、丁度今からXMLでプログラミングをと考えられている方にとっては
かえって参考になるかと思います (苦笑)
私は 今回のXML 関連の基礎的な情報については、下記の4つの資料を利用しました。
ここ最近は 以前に比べると 遙かにXML関連の日本語書籍は増えてきました。本屋で
どの本を買うべきか 悩むことが可能になってきたほどです。
XMLの基礎的な内容については、『よくわかるXMLの基礎』をかなり参考にしました。プログラミングする以前に必要な最低限の知識を得ることが出来ました。<2000/06/11 追記>
一方 <2000/06/11 変更>実際にプログラミングをするために必要な内容が載っていて
かつ 最新の動向に対応した情報が載っている日本語書籍は
執筆時点では 意外に少なく、結果的に 上記の3書籍を活用することになったのです。特に
JAVA PRESS の Vol.6 Vol.10 の号は大変参考になりました。SAX関連情報や
ProjectX , XML4J のプログラミングに関する記述も含まれているのです。これらバックナンバーは既に入手が困難である可能性もありますが、是非
取り寄せて 併せて見ていただければ 理解しやすいかと思います。
また 『The XML companion Second Edition』
は 主に裏付けを取るために利用しました。リファレンスとして
良くできているのでは無いかと思いました。ただ
私は英語は得意では無いので、あまり上手に活用は出来ていないかも知れません。しかし
最近のXML情報を紙の形式で得ることが出来るのは
大変嬉しかったです。
| Apache動向 |
どうもApacheって聞くとApache HTTPサーバの印象が強く誤解されがちかも知れません.実際そういう方もいらっしゃるかも知れませんね.それを払拭するために,あらかじめ
『Apache Software Foundation』(http://www.apache.org/) の全体的な活動について簡単に述べておきましょう.
Apache Software Foundation には 執筆時点において
主なものだけで下記のように多岐のプロジェクトがあります.
なお Apache HTTP Serverの成功は『アパッチ・ソフトウェア・ライセンス』というライセンスの特徴が大きな一因であったとも言われています.これについては
別途後述します。<2000/06/11 画像を更新>
| XMLパーサーの世間動向 |
XMLパーサーに着眼して その世間動向を簡単に見てみようと思います.主に無料のものに重点を置いて考えてみます.みなさんの中には
XMLパーサーと聞くと,IBM alphaWorks の XML
Parser for Java (http://www.alphaworks.ibm.com/tech/xml4j) (以降 IBM XML4J) を思い浮かべる方も多いことと思われます.実際
現時点において XMLを生成したり分析したりする機能を含んだシステムを自作するなどの構築事例には
IBM XML4J を利用しているケースがとても多いように見受けられます.
実は Apache Xercesシリーズは IBM XML4J ととても深い関係があります.Apache
Xerces for Java (以降 Xerces-J) は IBM XML4J
のソースコードをベースに開発されたものだったのです.そして今や
IBM XML4J (3.0.1) 自身が Xerces-J (1.0.3)
をベースにするように書き換えが行われました.IBM
XML4J (3.0.1) に含まれるライブラリは 既に
バイト数換算で 99%以上が Xerces-Jで占められています。(xml4j.jarは
10,002バイトしか無いのです。) これは Apache
Xerces-J の成果が IBM自身にフィードバックされた良い例ですね.余談ですが、IBM
XML4J は 以前は少しやっかいなライセンス下にあったのですが、<2000/06/11 修正: 以前のライセンス形態を調べてみたのですが
調査不能でした。XML4J 2.x代のアーカイブがあれば
その中のライセンスを見て判断できるとは思うのですが、、、すみません。>現時点では何とアパッチ・ソフトウェア・ライセンスに準拠するよう変更されています。(いま確認して びっくりしました。)
また一方 XMLパーサー と聞いて,サン・マイクロシステムズ
Java API for XML Parsing (http://java.sun.com/xml/download.html) (以降 サン JAXP) を連想される方もいらっしゃる事でしょうね.XMLをするならJava
→ Javaで書くならサンのAPI → サン JAXP という
ごく自然で正統派な連想です.でも 実は Apache
Xerces-J は サン JAXP とも深い関係があるのです.JAXPは
既に正式版 (1.0.1) がリリースされていますが、この
JAXP の デフォルトのパーサーであるSUN Java
Project X も Xerces-J に提供されているのです。
Apache XML Project の Xerces (XMLパーサー)
に関しては IBMとサン・マイクロシステムズがお互いソースコードを提供し合うということで開始されたのです.IBM
XML4J および サン JAXP と Xercesとの関係については,後で詳しく述べています.
それ以外のものとしては,Java Document Object
Model (http://www.jdom.org/index.html) (以降 JDOM) というXMLパーサーがあります.これは
Apacheライクなライセンス形態を取っています.SAXの効率良さとDOMのプログラミングの簡単さの両方のいいところを統合して提供することを目指しています.JDOMをダウンロードして解凍してみたら
xerces.jarが含まれていて思わずほほえんでしまいました。(JDOMは
デフォルトで Xerces-Jを利用するのです。)<2000/06/11 追記: 特徴を追記>また Oracleデータベースと関連の深い Oracle
XML Parser for Java V2 などもあります.これは Oracle XML Developer's
Kit (XDK) (http://www.oracle.com/xml/) の中に含まれます.XDKには データベースに関わるXMLツール類が多く含まれているので、Oracleな人には便利でしょうね。<2000/06/11 追記: 特徴を追記>
これ以外にも 私の知らないものや取り上げなかったものなど
多数あるのでしょうね.しかし実際の構築事例で使われているのは
第一バージョンのリリースタイミングなどの都合から
IBM XML4J が大半なのだと思われます.これは雑誌記事などの事例などでXML4Jが扱われている量や
世間でリリースされているパッケージソフトウェアの採用ライブラリ事例から見ても,妥当な判断であろうと思われます.(意外なほど多くのパッケージソフトが
XML4Jを利用&依存しているのです!)
それでは XMLパーサーだけに関して言えば,Apache
XML Project のなんて気にせず IBM XML4J だけ見ていれば良いのかといえば
それはとんでも無い事で,むしろ IBM XML4J
に関わってきて良い評価を持っている 或いはこれから関わっていこうと考えているからこそ
Apache XML Project を意識すべきなのです.
| Apache XML Projectが開始されるまでの経緯 |
Apache XML Projectの歴史は ごく短く,1999年11月から開始されています.このプロジェクトが開始された経緯については,1999年11月9日付けの
Apache XML Project のプレスリリース (http://xml.apache.org/pr/0001.txt) に詳しく見ることができます.このプレスリリースについて
ざっくりと紹介いたします.
まずプレスリリースの冒頭で Apache XML Projectを構成すべく
Bowstreet,DataChannel,Exoffice,IBM,ロータス・デベロップメント,サン・マイクロシステムズの各社が名を連ねています.プロジェクトの大目標は,「急激にXMLが採用されることによって発生したオープンソースな
XML・XSLの需要に応えること」なのだそうです.この目標のために,これら各社+αはプロジェクト開始時に
下記のようなソフトウェア群を寄付し合ってスタートすることにしたのです.
これらを元に,例えば Xerces (XMLパーサー)
については最初のバージョンは IBM XML4J 及び
XML4C ベースで行き,その次バージョンで サンのパーサーやその他の寄付ソフトから最も良い部分を編入していく予定になっていました.(後で述べますが
サンのパーサーの提供が 少し遅れました.つい最近ようやく提供が実現されています)
私のオープンソース運動の理解不足,想像力不足,或いは
日本企業の手による オープンソース運動事例の少なさが原因でしょうか,このように企業が強く関与したオープンソース運動というのはさすがに
にわかには信じがたいように感じられます.しかし
IBM XML4J のウェブページ (http://www.alphaworks.ibm.com/tech/xml4j) には執筆時点で 「IBMは、Apache Xerces-J
のコードベースへの主要なコントリビュータです」と高らかに謳われています.しかも前に述べたように
IBM XML4J の最新版は Apache Xerces-J をベースにするよう書き換えられていて,寄付やコントリビュートの恩恵が
自分自身でも得られているのですね.また これは私の推測ですが,Java
や XML を流行らせる事こそが IBMやサンの目標の一つでもあるのでしょう.
なお 私は これらの経緯については CNET JAPAN
のニュースで最初に知りました.
ご興味がありましたら、上記ニュースに プレスリリースを併せて読むと
わかりやすいと思います.なお サンからApacheへのソースコード提供の成果は
2000/04/06 頃に既に crimsonとして実験リリースされています.この頃
提供されたのでしょうね。これは Apacheのウェブページやダウンロードコーナーなどから知りました.ただし
残念なことに 現時点での最新版 Xerces-J (1.1.1)
には このサン提供のソースコードは反映されてはいません.
| アパッチ・ソフトウェア・ライセンス の簡単な紹介 |
ここ最近 オープンソースやGNUスタイルやLINUXスタイルの開発などについて取り上げられることが多いようですが、『アパッチ・ソフトウェア・ライセンス(The
Apache Software License, Version 1.1)』 についてもオープンソース運動
(http://www.opensource.org/) に該当するのだと言われることがあります.このライセンスについて、利用者の利点の一つに
ライセンス条件下においてバイナリおよびソースコードが無料で開示され,またバイナリに関して無料で再配布が可能な点が挙げられます.同じくオープンソースなライセンス形態を持っているものとしては
Perl,BIND,sendmailが並び称されることが多いです。
様々な点で無料であると同時に 利用者が開発に参加できるようになっていることも
オープンソースなライセンス形態の利点であると言われています。このため
そのソフトウェアの需要およびボランティア参画意欲など条件がツボにハマったプロジェクトは機能追加や品質向上が画期的に迅速になる可能性があります。
Apacheの各プロジェクトは これら利点を持った『アパッチ・ソフトウェア・ライセンス』及び理念に則って、ウェブサーバでの成功事例を
ウェブサーバ以外のインフラソフトウェアについても
実現して作ってしまおうという意欲的な活動なのです
このソフトウェアライセンス については http://xml.apache.org/dist/LICENSE.txt を見ると最も正確に理解できます.これを かいつまんで簡単な説明をさせて頂きます.
このソフトウェアライセンスは 基本的には ソース・コードおよびバイナリー形式の再配布について,指定されている版権情報,指定されている条件および否認リストを保持する必要があります.条件や否認リストに関しては
原文をそのままご参照ください.無保証・無損害賠償などを承諾する旨の記載があります.
ドキュメンテーションが存在する場合は、それにも同様に上記の版権情報や条件および否認リストなどの記載が必要になります.それ以外にも幾つかの追加条件があります.世間のソフトウェアなどは
このライセンス記述を原文全て そのままの形で張り付けて提供するのが一般的なようでして、IBM
XML4J も 現在は そのような画面で提供しています。ただし
私は法律の専門家でも何でも無いので 誤りが含まれる可能性があります。必ず原文を
併せてお読みいただくようお願いいたします。
「オープンソースで無いとソフトウェアでは無い」などの過激な哲学の人ならずとも このようなオープンソースなライセンス形態を望ましく感じる人は多いでしょう.Apache XML Project も このライセンス形態を取っているので、判断する際の好材料のひとつとなります.機能的に魅力的であって、かつライセンス形態が好ましい(無料)だと来れば 選択してみたくもなりますよね。
さて いよいよ 各サブプロジェクトの概要に迫っていこうと思います.
| Xercesシリーズ概要 |
XMLパーサーなどの機能を提供するXercesシリーズですが,現在
Xercesシリーズには Java版,C++版,Perl版のラインナップが存在します.XMLをやるのならJavaだろう(笑)
という先入観を持っていると意外なのですが,C++版などJava以外の言語版もあるのは
一層嬉しい事であるように感じられます.もっとも
移植性(含むGUI)やUNICODEの扱い易さなどを考え出すと,Javaが最も入りやすそうです.今更C++なんて携わりたくないという方も多いでしょうね
:-)。IBM XML4J ユーザなど Xerces-J の潜在的な需要もあるでしょうから、興味を持っておられる方も多いのでしょう.ちなみに
私は Javaを用いた パッケージソフトやシステム寄りソフトが守備範囲としているので
Apache XML Project の中ではXerces-J が最も気になる存在なのです.
| Xerces for Java 概要 |
XMLパーサーであるXerces-J 1.1.1 <2000/06/11 変更> は XML1.0 recommendation 推薦をサポートし,業界標準のDOMレベル1とSAXバージョン1
APIを実装しています.これに加えて XMLスキーマ,DOMレベル2バージョン1.0,SAXバージョン2をサポートしています.ただし
標準が決まっていない範囲についても積極的に実装が行われているので,既存のAPIなどが永続的であるというわけでも無いそうです.
たとえば XMLスキーマサポートはαな状態,DOMレベル2サポートはβな状態という位置付けであるとウェブページには記載があります.(SAX2は正式対応済) <2000/06/11 変更> もっとも これらは標準が定まる前の状態の仕様に関して
強く意欲的に実装を行っているための現象でして,逆に
むしろIETFやW3Cなどの標準の側が Xerces-J
に標準を合わせていくというケースも出てくるでしょうね.その点も
Xercesシリーズ開発の目的の一つであるそうです.業界標準なんてものは
そもそも実際の実装があって初めて定義できるような向きもありますね.Xercesシリーズは
その業界標準自身へのフィードバックや 作業中の業界標準のテスト的実装を果敢に行っていき,業界標準確立を強く前進してくれることと期待しています.他方
そのプロジェクト体制の特徴ゆえに 結果的にデファクトになりうる素養を十分に持っています.(と
私は予想しています)
| Xerces for C 概要 |
XMLパーサーであるXerces-C 1.1.0 も XML1.0
recommendation 推薦をサポートし,業界標準のDOM1.0,SAX1.0,Namespacesをサポートしています.また
DOMレベル2バージョン1.0 も実験的に実装されています.また
UNICODE3.0規格に従っているのだそうです.バージョン番号の大小関係とは無関係に,Xerces-J
の方が Xerces-Cより 実装済み範囲が大きいように見受けられます.また
Java版とは異なり C++版には対応プラットフォームの表示がありました.(対応プラットフォームという概念があるのは
C++としては 当たり前といえば当たり前なのですが,これが
どっぷりJavaな思考のもとで考えてみると 意外にすら思えてきたりします。また
意外性のあるものとして,Microsoft MSXML parser
との互換性を供給するための Xerces-C用COMラッパーなんてものすら提供されていたりします.:-)
| Xerces for Perl 概要 |
Xerces-P 1.0 は,Perl5 から XML4C DOM Parser
が使えるようなラッパーオブジェクトを提供します.DOMレベル1が機能提供範囲であるようです.ただし
私は Perlに対して全く理解がありません.この程度でとどめておきますね.
| Xalan概要 |
XMLドキュメントをHTML,テキスト,他のXMLドキュメントタイプに変換するためのXSLTプロセッサーです.Xalan-J
1.0.1 では W3C の XSL Transformations (XSLT)
と XML Path Language (XPath) を満たしています.実行には
Xerces-Jが必要なのですが,Xalanのダウンロードに
Xerces-Jが予め含まれるようなっています.XMLをベターなHTMLとして扱おうとしている方々で
サーバ部分は手作りなんて方にとっては,Xalanサブプロジェクトは有意義なプロダクトである場合もありそうですね.
| FOP概要 |
XSLフォーマットオブジェクトで駆動される 世界最初のプリントフォーマッタなのだそうです.これは フォーマットオブジェクトツリーを読み込んで PDFに書き出すJavaアプリケーションです.0.13.0 というバージョンがダウンロードコーナーに載っていました.これを実行させるためには下記のソフトが必要なようです.
| Cocoon |
Cocoonは,新しいW3Cテクノロジー(例えばDOM,XML,XSL)に頼った,ウェブ・コンテンツを提供するための100%
pure java な XMLパブリッシュフレームワークです.これを
ドキュメント・コンテンツ,スタイル,ロジックの3層に分離して提供しようとするものであるようです.これにより
同一データを HTMLクライアント,PDFクライアント,WMLクライアント各々に提供したりすることが可能になるそうです.
Cocoonに関しては,現在 次期バージョンに該当するCocoon2
というのがα版レベルで進んでいます.「ピラミッド・モデル」という既存版Cocoonとは異なる新たなモデルを採用しているようです.XMLをベターなHTMLとして扱おうとしている方々で,統合パッケージソフトを探している方にとっては,Cocoonサブプロジェクトは有意義なプロダクトになる可能性もあるのでは無いでしょうか.
| Xang |
Apache Xang Project の他のサブプロジェクトの成果物上で動く,Javaによる動的サーバページ開発環境なのだそうです.データドリブンなクロスプラットホームのウェブアプリケーションを構築することが可能になるそうで,アーキテクチャ的にはデータ,論理,プレゼンテーションとを分けるようするとのことです.技術的にはHTTP,XML,XSL,DOM,ECMAScript (JavaScript) といったオープン技術で構成されます.ダウンロードコーナーには Xang 0.0.2 が載っかっていました.これを動かすためには,下記のソフトをそろえる必要があるのだそうです。
Hello World 的なサンプルは動作させられる風に記載がありましたが,,,.ちょっとした環境を構築して動作させるだけでも大仕事って感じですね.一方
この Xangサブプロジェクトまで来ると Apache
HTTP Server と何だか関係しているというか関係がありそうな風味があって良いですよね(!?).(まだ
Apacheという名称の呪縛から抜け切れていませんね
:-)
| SOAP |
<2000/06/11 追記: SOAPについての記載を開始>
Simple Object Access Protocol という 同名のW3Cプロトコル(http://www.w3.org/TR/SOAP/) の実装です。IBM SOAP4J をベースにし そしてそれを取って代わるものとされるそうです。
XML で メッセージ処理・エンコード・RPCを実現するものなのだそうで、ミドルウェアフリークな方には面白く感じられると思います。
なお SOAPは 執筆終了ぎりぎり間近にリリースされた関係上、Apacheのウェブページなどからは
ほとんど情報が得られませんでした。
| Xerces-J を実際に使ってみる |
では Xerces-Jを実際に利用してみましょう。
『ダウンロード』
ダウンロードは Apache XML Project (http://xml.apache.org/) 下のダウンロードコーナー http://xml.apache.org/dist/xerces-j/ から
の3つを取得しました。tar.gz形式とZIP形式の2方式で提供されていますが、JDKがインストールさへされていれば
プラットフォームを問わず扱うことが可能なZIP形式の方を選択しました。<2000/06/11 大幅に変更: Xerces-Jの実行例もZIPで扱われていましたし、根本的に
ZIP形式の方がJDKが入っている場合有利なのです。>
なお執筆時点で 丁度 Xerces-J 1.1.1 がリリースされましたので、実際の動作の確認などに
これを利用しました。Xerces-J最新版の ftpサイト上でのファイルの日付は 2000/06/05
でした。<2000/06/11 1.1.1の内容に更新>
『付属サンプルの展開&実行』
それでは 最初にダウンロードしたアーカイブに付属するサンプルコードを実行してみます。このようなライブラリAPIの理解の目的で
付属サンプルを動作させるのは よく使われる手口です。
さしあたり展開実行に際して、私は
に格納して解凍しました。Xercesに関しては
ソースコードとコンパイル後イメージを同一ディレクトリに展開すると
訳が分からなくなるおそれがあるため このようにしました。みなさんが実際に試される場合は
ディレクトリ名を適宜読み替えてください。解凍には JDK付属のjarツールを利用しました。<2000/06/11 変更>
解凍後 C:¥apache¥bin¥xerces-1_1_1¥docs¥html 以下のディレクトリに 付属サンプルの簡単な説明が載っています。(これは
インターネット上に載っているウェブページと同等なものであるようです)。ここで注意を促したいのですが、htmlドキュメントに関しては
bin側に含まれるドキュメントを見る必要があります。src側に含まれるドキュメントは
何とドキュメントのソースコードなので、そのままでは閲覧できません。<2000/06/11 追記> GUIなサンプルの実行方法に 少し食い違い(格納パッケージが変更されている)
がありましたが、こちらで だいたいの雰囲気がつかめると思います。
さしあたり コンパイル後イメージの C:¥apache¥bin¥xerces-1_1_1
ディレクトリに移動して サンプルを実行します。サンプルに関してもコンパイル後のJARファイルが格納されているのです。最初に
見栄え系サンプルで 気に入ったものから紹介します。Java2
SDK 1.2.2 などが適切にセットアップされていれば、
| java -classpath xerces.jar;xercesSamples.jar ui.TreeViewer data¥personal.xml (この部分などが 付属HTMLと食い違います) |
で実行することができます。<2000/06/11 画像更新。バージョンアップにより内容が変わっていまして、そのため画像更新が必須になります
(T_T)>
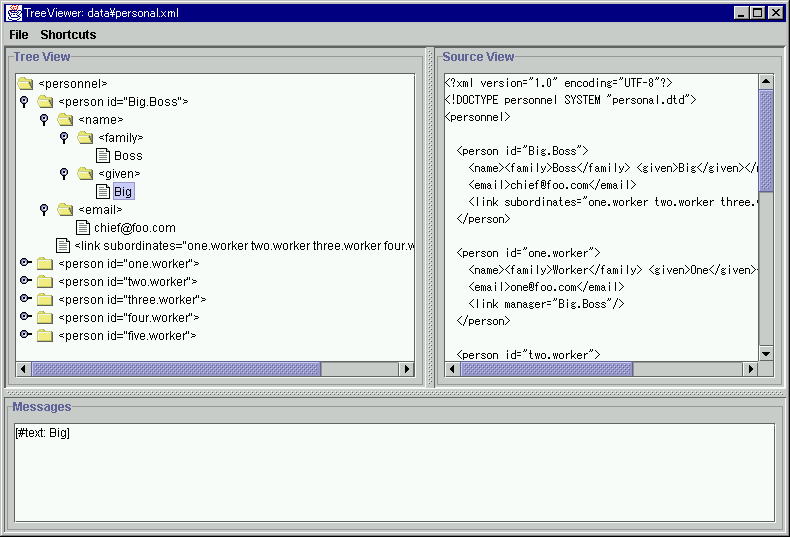
XMLファイルを入力として ツリー表示を行うサンプルプログラムです。右側に
入力ファイルである XMLのソースコードが載っています。見栄え系ソフトは
いいですね。XMLソースコード確かにパースされていますよ
っていう現象&事実が 見栄えによって 強く印象づけられます
(笑) また このサンプルプログラムのソースコードが入手可能であることも
嬉しいことです。(先ほどダウンロードしたソースコードの中に
ライブラリ部分もサンプル部分も全て含まれているのです)
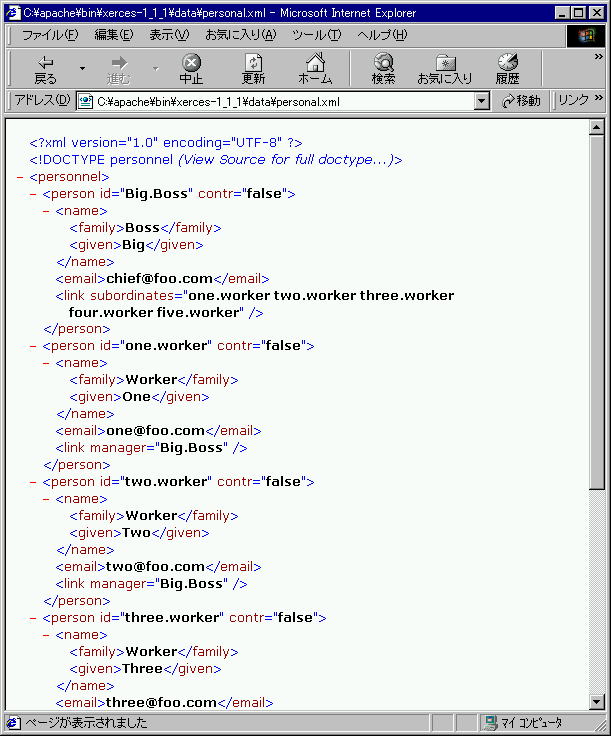
なお このXMLソースコードの中身を 例えば Microsoft
Internet Explorer 5.0を使って そのまま開くと
このように表示されます。(後述のコマンドラインサンプルの方も
このデータを利用します) <2000/06/11 画像更新>
『付属サンプルの展開&実行 その2』
では 続いて コマンドラインなサンプルを実行していきます。残念ながら
コマンドラインサンプルの方は 一発動作&一瞬理解
という訳には行かないようです。
まず SAXCount という SAX系サンプルを動かしてみます。SAXは
Simple API for XML の略だから 私のような初心者にとっても簡単なのだろうという読みです。(乱暴に
簡単XML用APIって訳しました。その直後 この推測は
見事にはずれてしまいます)
| C:¥apache¥bin¥xerces-1_1_1>java -classpath
xerces.jar;xercesSamples.jar sax.SAXCount
data¥personal.xml data¥personal.xml: 651 ms (37 elems, 12 attrs, 0 spaces, 268 chars) |
これだけでは 何のことかわかりませんね (苦笑)
先に解凍しておいた ソースコード (C:¥apache¥src¥xerces-1_1_1¥samples¥sax¥SAXCount.java) を併せてみてみます。すると なるほど、パースの挙動を行って
それで終わりというサンプルであるということがわかります。だがしかし
このサンプルをよ〜く読んで見て はっと気がついて腰が引ける方も多いかと思います。というのも
このサンプル自身 コールバックの嵐で 『いつ
なにが どこで ど〜して』 というのが ぱっと見は不明だろうだからなのです。古典的プログラマーには
プログラムの動作の流れが全く見えないと思われます。ライブラリからどしどしコールバックで呼び出されるのです。従来型プログラミングパラダイムをスパゲッティープログラミングと呼ぶのでしたら、さしずめ
コールバックプログラミングパラダイムは マカロニプログラミングとでも呼ぶのでしょうかね。JAVA
PRESS Vol.6 にも書いてあるように、多量データをパースする際には
実装上の問題から DOMでは実装不可能で SAXスタイルで開発せざるを得ないケースがあるのでしょう。しかし
大量データで無いのでしたら、このSAXプログラミングは
私はできれば避けたいように思いました。
| SAXCount.javaの一部。このようにコールバックに処理が行われます。イベントドリブンって感じたら
別に普通と言えば普通なのですが、取っつきは悪いです。 ----------前略---------- // // DocumentHandler methods // /** Start document. */ public void startDocument() { 【補足説明: ドキュメント開始時に呼ばれる】 ----------省略---------- } // startDocument() /** Start element. */ public void startElement(String uri, String local, String raw, Attributes attrs) { 【補足説明: エレメント開始時に呼ばれる】 ----------省略---------- } // startElement(String,AttributeList) /** Characters. */ public void characters(char ch[], int start, int length) { 【文字が来たときに呼ばれる】 ----------省略---------- } // characters(char[],int,int); /** Ignorable whitespace. */ public void ignorableWhitespace(char ch[], int start, int length) { ----------省略---------- } // ignorableWhitespace(char[],int,int); ----------中略---------- /** Returns a string of the location. */ private String getLocationString(SAXParseException ex) { ----------省略---------- } // getLocationString(SAXParseException):String ----------後略---------- |
続いて DOMCount という DOM系サンプルを動かしてみます。
| C:¥apache¥bin¥xerces-1_1_1>java -classpath
xerces.jar;xercesSamples.jar dom.DOMCount
data¥personal.xml data¥personal.xml: 671 ms (37 elems, 18 attrs, 140 spaces, 128 chars) |
これも 実行結果だけ見ていると泣けてきます。この出力結果からだけでは
『少なくとも SAXCountよりは低速であろう』
程度しか読みとれません。同じように 先に解凍しておいたソースコード
C:¥apache¥src¥xerces-1_1_1¥samples¥dom¥DOMCount.java を見てみます。幸いなことに 先の SAXCount.java
よりは ずっと簡単であるように思えます。(先に難解なものを見ておくと
こういう時 なんとなく救われます)
パーサーを作って→パースして→traverseの箇所で集計処理
していることがわかります。(しかしそれでも
traverse自身を再帰処理しているから 再帰に馴染み無い方には
少しつらいですね。それでも コールバックの嵐よりはずっとマシでしょう。)
traverseの箇所では パース結果オブジェクトを使って
集計処理をしています。これから 確かにパースできているのだなと感じ取ることが出来ます。
さらに続いて DOMWriter という DOM系サンプルを動かしてみます。
| C:¥apache¥bin¥xerces-1_1_1>java -classpath
xerces.jar;xercesSamples.jar dom.DOMWriter
data¥personal.xml data¥personal.xml: <?xml version="1.0" encoding="UTF-8"?> <personnel> <person contr="false" id="Big.Boss"> <name><family>Boss</family> <given>Big</given></name> <email>chief@foo.com</email> <link subordinates="one.worker two.worker three.worker four.worker five.work er"></link> </person> <person contr="false" id="one.worker"> <name><family>Worker</family> <given>One</given></name> <email>one@foo.com</email> <link manager="Big.Boss"></link> </person> ・・・中略・・・ </personnel> |
もちろん 入力XMLファイルをそのまま画面表示しているだけではありません。誤解しないでくださいね。(私は最初誤解しました
:-) ソースコード (C:¥apache¥src¥xerces-1_1_1¥samples¥dom¥DOMWriter.java) をごらんになられるとわかるように、パース処理したあと
パース結果を再度 XML適合形式で標準出力に書き出しているのです。
パーサーを作って→パースして→printの箇所で
XML形式で出力
の順で処理が記述されていますね。
このプログラムは DOMCount.java の後に見ると
段階的(差分的) に読みとることができるので
まだ理解しやすいかと思います。
さらに続いて DOMGenerate という DOM系サンプルを動かしてみます。<2000/06/11 変更: Xerces-Jには crimsonとは別の 新たな書き出し機能が提供されている>
| C:¥apache¥bin¥xerces-1_1_1>java -classpath
xerces.jar;xercesSamples.jar dom.DOMGenerate STRXML = <?xml version="1.0" encoding="UTF-8"?> <person><name>Jeff</name><age>28</age><height>1.80</height></person> |
Xerces-J 1.1.1 から新たに加わった このサンプルは
DOM書き出しを実現する方法の一つとして示されています。たったこれだけの行数で
XMLが生成できると嬉しくなってしまいますね。
なお 残念なことに このDOM書き出しは crimsonと呼ばれている
SUN ProjectX該当個所とは異なる実装であるようです。この記事で取り上げているJAVA
PRESS バックナンバーを通読されている方々や
IBM XML4Jに通じてられる方々のために 多少の詳細情報を補足しておきます
なお crimson に関しては、正式に Xerces-J
に取り組まれた際に どのような形になるのか不確定なので、これ以上は取り上げません。実際
今回取り上げているバージョンの 1.1.1 には
既に別のDOM書き出し実装が組み込まれており、今後
DOM書き出しの実装がどのようになるのか 余談を許さない状況であります。
『自作確認ソフトの作成と実行』
付属サンプルを動かして感触がつかめてきたので、いよいよ自分でコーディングしてみます。
新しいプログラミングAPIを理解するには 読み書き ができれば かなりの部分が理解できると私は思っています。今回も
XMLの読み書きを行ってみようと思います。
最初にXMLを書く側から作ってみます。
Documentの作成のためのソースコードとしてTest.javaを作成しました。Test.javaを見ていただければわかりますが、これ自身は
ものすごく簡単なプログラムですね。
コンパイルは 下記の手順で行います。
| set XERCES_PATH=C:¥apache¥bin¥xerces-1_1_1 javac -classpath .;%XERCES_PATH%¥xerces.jar *.java java -classpath .;%XERCES_PATH%¥xerces.jar Test |
これを実行すると Test.xml というXMLファイルが生成されます。このサンプルではエンコードをSHIFT_JISに切り替え可能なようにしてあります。(ただし
SHIFT_JISエンコードだと 正当だけれども美しくないXMLが生成されてしまいます。)
また 生成されたXMLのための DTDを簡単に作ってみました。
Test.dtd <2000/06/11 変更しました>
| <?xml encoding="Shift_JIS"?> <!ELEMENT よく見るウェブページ (URL)+> <!ELEMENT URL (題名,アドレス,コメント)> <!ATTLIST URL id CDATA #REQUIRED> <!ELEMENT 題名 (#PCDATA)> <!ELEMENT アドレス (#PCDATA)> <!ELEMENT コメント (#PCDATA)> |
DTDを準備したので、IEで表示できますね。 Internet
Explorer 5.0 での表示結果は下記のようになります。
<2000/06/11 画像更新>
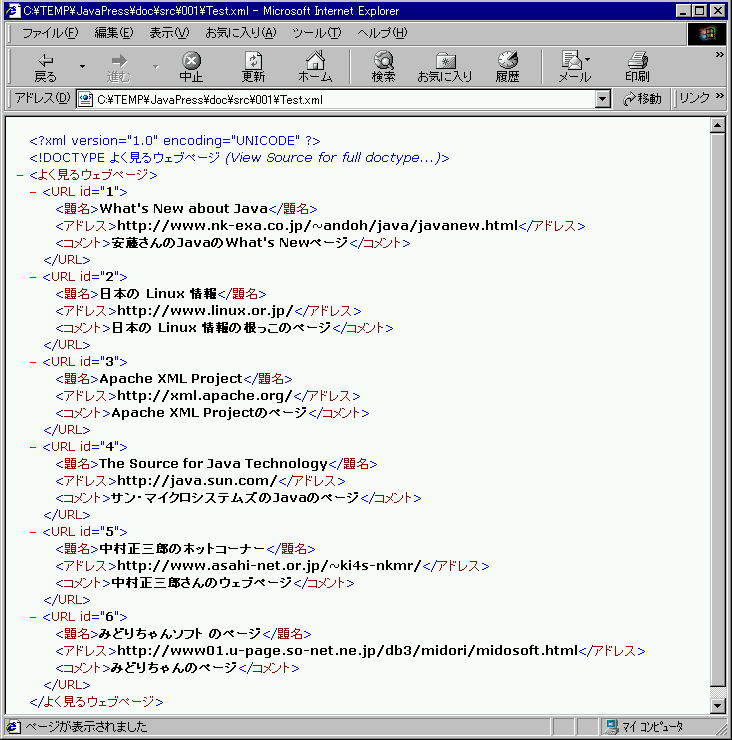
ちなみに 内容そのものについて あまり悩まれないように。
さて、DTDというか構造の設計に関して、私は
どうも HTMLの呪縛から逃れられていない DTDであるように見受けられます。後で読み出す側を自作をしてみると、読み出す側の都合的には、もっと属性(アトリビュート) を有効活用したほうが楽であるケースも多いようです。要素(Element)
で提供するのか もしくは 属性(Attribute) で提供すべきかの判断は
意外に難しいものでもあるようですね。(『よくわかるXMLの基礎』には
そのように記載がありました。:-) <2000/06/11 追記> これは 設計レベルの話なので、このくらいでとどめておきましょう。
XML読み出しの実装
XML書き出しの実装が確認できたところで、今度は
このデータを読み出す処理を作ってみましょう。
ソースコード Test2.javaは こんな感じになります。また これのコンパイル&実行結果は下記です。<2000/06/11 内容更新>
| C:¥TEMP¥JavaPress¥doc¥src¥002>set XERCES_PATH=C:¥apache¥bin¥xerces-1_1_1 C:¥TEMP¥JavaPress¥doc¥src¥002>javac -classpath .;C:¥apache¥bin¥xerces-1_1_1¥xerces.jar *.java C:¥TEMP¥JavaPress¥doc¥src¥002>java -classpath .;C:¥apache¥bin¥xerces-1_1_1¥xerces.jar Test2 題名: What's New about Java アドレス: http://www.nk-exa.co.jp/‾andoh/java/javanew.html コメント: 安藤さんのJavaのWhat's Newページ 題名: 日本の Linux 情報 アドレス: http://www.linux.or.jp/ コメント: 日本の Linux 情報の根っこのページ 題名: Apache XML Project アドレス: http://xml.apache.org/ コメント: Apache XML Projectのページ 題名: The Source for Java Technology アドレス: http://java.sun.com/ コメント: サン・マイクロシステムズのJavaのページ 題名: 中村正三郎のホットコーナー アドレス: http://www.asahi-net.or.jp/‾ki4s-nkmr/ コメント: 中村正三郎さんのウェブページ 題名: みどりちゃんソフト のページ アドレス: http://www003.upp.so-net.ne.jp/midori/midosoft.html コメント: みどりちゃんのページ |
出力結果の形式を独自のものにすると さすがに
『パースが実際に行われているんだな』って感じることが出来ます。(苦笑)
なお 出力結果の作りは JAVA PRESS Vol.6 を
少し参考にしました。(そうなんです。Vol.6を見て アトリビュートを使えば良かったかなって
少し反省したのです :-) <2000/06/11 削除>
XMLの正当性チェック
Xerces-J付属サンプルを用いて 今回生成したXMLの正当性チェックを行ってみましょう。Xerces-J
のパーサーの部分には 正当性チェックの機能も併せ持たされていて
そこがチェックを果たしてくれるようなっています。これは
例えば DTDファイルを削除してXMLからDTD関連の記述箇所を削除して実行すると
エラーが表示されることにより 確認できます。
DOMCount による実行結果は下記のようになります。なお XMLファイルのディレクトリ位置は 適宜読み替えてください。
| C:¥apache¥bin¥xerces-1_1_1>java -classpath
xerces.jar;xercesSamples.jar dom.DOMCount
C:¥TEMP¥JavaPress¥doc¥src¥002¥Test.xml C:¥TEMP¥JavaPress¥doc¥src¥002¥Test.xml: 671 ms (25 elems, 6 attrs, 0 spaces, 426 chars) |
DOMWriterは 下記のようにエンコード指定をすれば
うまく日本語表示できるようになります。(本当は
指定なしでも正常に動いて欲しいのですが、、、
(^_^;)
| C:¥apache¥bin¥xerces-1_1_1>java -classpath xerces.jar;xercesSamples.jar dom.DOMWriter -e SHIFT_JIS C:¥TEMP¥JavaPress¥doc¥src¥002¥Test.xml |
面白いところでは、先に紹介した GUIサンプルでの実行結果です。XMLファイルのディレクトリ位置は 適宜読み替えてください。コマンドラインは下記のようになります。
| C:¥apache¥bin¥xerces-1_1_1>java -classpath xerces.jar;xercesSamples.jar ui.TreeViewer C:¥TEMP¥JavaPress¥doc¥src¥002¥Test.xml |
これの実行結果は下記のようになります。
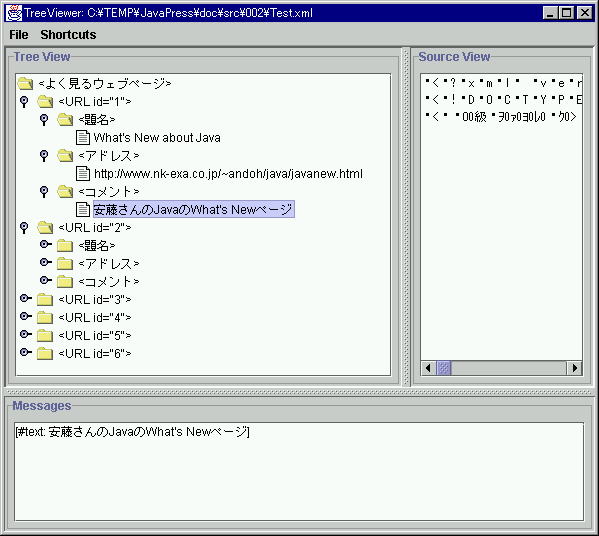
こちらのサンプルは 少し悩ましいことに SHIFT_JISエンコードだと
何も手を加えずとも日本語が通るのですが、UNICODEだと
手を加えないと日本語は通りません。悩ましいです。
また 今回生成した XMLも さしあたっては正当なXMLデータになっているようなことが
これで確認できました。例えば 故意に DTDやXMLを破壊すると
サンプルの正当性チェックにて引っかかることも確認できます。
| おわりに |
Apache XML Project 全般から始まり、Xerces-J
に関わる背景、歴史、そして サンプルコードの実行から
実際に APIを利用したプログラミングまで、一通り紹介させていただきました。どうだったでしょうか?Apacheでの成功体験を
XMLパーサーやXML関連プロダクトに反映させてしまおうという
意欲的な取り組みについて、少なからず期待してしまうのは
私だけでは無いと思います。
XMLパーサー Xerces-J に着目して言えば、同様な機能性を持った
IBM XML4J や SUN JAXP などがありますが、しかし
むしろ逆で IBM XML4J や SUN JAXP (または
Project X ) の成果物を Xerces-J に統合してしまおうとする動きなどの動向については
具体的な成果がすぐにでも出せそうに感じられて、期待を越えて
実用性・実際の効果にすら興味が沸いてこられた方もいらっしゃるとも思えます。
Apache 関連プロダクトは アパッチ・ソフトウェア・ライセンスに則って運用されているので、ソースコードが公開されている利点や
無償入手ならびに無償再配布可能であるという点も
Xerces-J の魅力を増している一因なのでしょうね。その気があればXerces-J
の開発やドキュメンテーション作成に参加することも可能なのは
さらに興味深いです。(みなさんも 興味を持たれたら
是非参加を検討して欲しいです)
一方 Xerces-J の今後の課題ですが、現時点では crimsonと呼ばれている SUN Project X の成果部分のXerces-J への組み込みが一番重要でしょう。これにより 既存のXerces-J (狭義では IBM XML4J) と SUN Project X の融合がようやく実際に実現されます。書き出し機能の別な実装が提供されたとはいえ やはりcrimsonは統合して欲しいものです。これの実現により 私たち利用者の利便性は 更に向上することでしょう。
今後 IT技術やソフトウェア開発の現場において
XMLの占める重要性は ぐんぐんと上昇していくことでしょう。みなさんが
XML活用に順調に入ることができるよう祈っています。また
この記事が XMLを扱う 或いは扱おうとされている方々のお役に
たてることが出来れば幸いです。
| 参考文献など |
http://xml.apache.org/ 以下 および 各々 対応するウェブページ
『よくわかるXMLの基礎』 著者:Simon St.Laurent
訳者:藤本叔子 発行:日経BP社 ISBN4-8222-9110-3 <2000/06/11 追記>
『JAVA PRESS Vol.6』 特別企画 XML&Java
新世紀の黎明
『JAVA PRESS Vol.10』 Project X で始めるDOMプログラミング
『The XML companion Second Edition』 著者:Neil
Bradley 出版:ADDISON-WESLEY
安藤さんのJava FAQ (What's New) (http://www.nk-exa.co.jp/‾andoh/java/javanew.html)
| 利用ソフト |
Java2 SDK 1.2.2_005 (Windows版)
IBM インターネット翻訳の王様 Power+ (3.5.2.9)
IBM ホームページ・ビルダー2001 (5.0.3)
秀丸エディタ 2.29
JUSTSYSTEM ATOK13
Microsoft Internet Explorer 5.0 (Windows版)
Microsoft WindowsNT4.0 SP6a
| 更新履歴 |