ここではアプリケーションのアーキテクチャー、設計を行うための指針について考えたいと思います。
システムの構築はいろいろな要素から成り立っています。機能を実現するための、アプリケーションだけでは成立しません。アプリケーションを支える、アプリケーションサーバなどのミドルウエア、それを支えるOS、さらにその下にハードウエアがあります。デスクトップアプリケーションであればミドルウエアは不要で大体アプリケーションとOSを考えればいいでしょうが、サーバアプリケーションとなると考えることはいろいろあります。
そのマシン単体では動作せず、クライアント機についても考える必要があります。そのクライアントとの接続にはネットワークが用いられます。ネットワークではケーブル、スイッチ、回線等いろいろ考慮することがあります。また一台のサーバですべてをこなすのではなく機能を複数のサーバに分割して構成するのが一般的です。
システム設計では、こういう構成から、運用・監視についても考慮します。ちょっとしたサーバアプリケーションであっても、検討しなければならないことは膨大にあります。某企業から出された要件定義書では、機能要件の何倍もの量のシステム要件が提示されたことがあります。
が、ここでは、システム要件ではなく、機能面に話を絞って、アプリケーションの構築について考えたいと思います。
プログラム、アプリケーションには様々なものがありますが、とどのつまり、要求されたことに対して結果を返すというものです。何かのきっかけを与えることで、人間があらかじめプログラムしたものを実行し、何らかの結果を出します。
OSも一種のアプリケーションで、ユーザの入力を待機して、入力内容に応じて、プログラムをロードし、CPU時間を割り当てて、制御をプログラムに移します。
プログラムにはいろいろあります。
・コマンド型(その都度起動して、処理が終われば停止) ・常駐型(起動後、意図的に停止するまで、リクエスト・タイマーイベントに応じて動作) サーバー型 Web、メール、Webアプリケーション、etc. アプリケーション型 エディタ、表計算、etc.
単純なものもあれば、複数の処理が同時に走り、他のアプリケーションと連動して、一連の処理を行うものもあります。
これを整理すると、いずれのプログラムも次の要素から成り立っています。
入力 - 処理 - 出力
コマンドラインから、dir \windowsと入力すると、プログラムが適切な処理をして、ディレクトリの中身を返します。あるいはWeb画面のフォームに値を入力して、登録ボタンを押すと、サーバ側で登録処理が行われて、結果を画面上に表示します。
このように入力と処理と出力を定義すると、仕様が出来上がります。
入力:フォームに値を入力し登録ボタンを押す。 処理:XXXテーブルにデータを登録する。 出力:登録が成功したか否かを表示する。
多くの場合、これだけだと不十分なので、条件を書き加えます。
入力:フォームに値を入力し登録ボタンを押す 条件:ユーザがすでにログインしていること 条件:フォームの内容が正しいこと 処理:USERテーブルにデータを登録する 出力:登録が成功したか否かを表示する
これをもう少しきちんと書けば仕様書になりますし、もう少し詳しくしたのがユースケースになります。
これをプログラムの観点から見ると次のようになります。
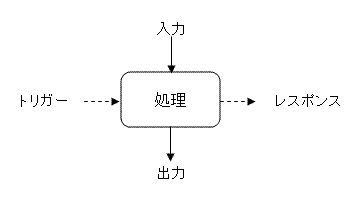
トリガーと入力を分けていますが、トリガーはあくまでもその処理を走らせるためのきっかけです。ユーザがボタンを押したとか、コマンドを実行したとか、タイマーイベントが走ったとか、他のシステムからアクセスされたとかです。
入力は、その処理を行うための様々な条件となります。設定ファイルの情報だったり、セッションやDBに格納されている値だったり、プログラムに渡された引数だったりです。コマンドに引数をつけて実行したとしても、引数だけがすべての条件ではありません。なので、トリガーはあくまでもコマンドで、引数やその他の条件はすべて入力とします。
Webアプリケーションでは、Submitを押して、あるpathへのリクエストがトリガーであり、パラメータやセッション情報等が入力情報となります。ただしアプリケーションサーバの立場から言うと、Pathも入力情報となります。どのレイヤーで考えるかで何が入力で何がトリガーかというのは違ってきます。
次に出力とレスポンスを分けていますが、ここで言うレスポンスとは処理の結果、成功したか失敗したかというだけです。出力は、ユーザに返される場合もあれば、DBやメモリに書き込んでユーザにはほとんど情報を返さない場合もあります。レスポンスに内容があれば出力も兼ねています。ただレスポンスの要素としては正常に返ってきたということだけで内容は問いません。例外が返ってきた場合はそれがレスポンスとなります。
このように5つの要素で整理すると、かなり処理の定義を明確にできます。
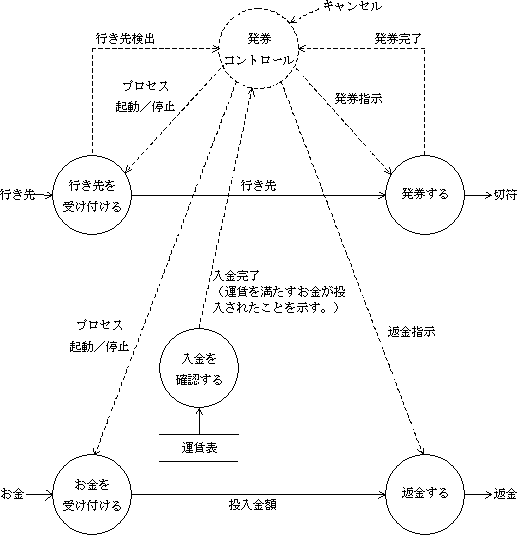
DFDを拡張したコントロールフロー図ではこの要素が盛り込まれています。
(IDEF0とは、インプット、コントロールの意味が若干異なる。DFDでのインプットは、IDEF0でのコントロールに当たるものが多い。)
こういう分析は、プログラム全体に対して行うこともできるし、メソッド単体に対して行うこともできます。メソッドの呼び出しがトリガーであり、引数・インスタンス変数・DBなどが入力であり、返り値がレスポンス、オブジェクトやDBの書き換えが出力になります。
プログラム、システム、アプリケーション、サーバー、オブジェクト、コンポーネントと呼ばれるものすべて同じように整理することができます。
アプリケーションは、デスクトップ、業務系、制御系などに分かれます。
データの扱いという観点からは、以下のように分類されます。
1.永続的なデータを扱う
2.セッションの間だけ状態を持つ
3.一度処理を行って状態は保持しない
1では、データベースが使用され、業務系はこのタイプです。デスクトップアプリケーションは2です。エディタなど起動している間は情報を保持します。ファイルに出力するという点では永続的データを扱っていますが、業務アプリケーションと違い、中身はフォーマットさえあっていれば問題にしないので2のカテゴリになります。
プロキシサーバなどは、正確には若干セッションを持つので2となりますが、3に分類されます。
それぞれによってアプリケーションの組み方は異なります。いずれもオブジェクト指向が適用できますが、1については私はデータ中心指向を思想的にはメインに考えたほうがいいと思います(こちら参照)。
入力 - 処理 - 出力
をもう少し細かくすると、多くの場合、入力チェック(Validation)をメインの処理の前に行います。そして各処理の間ではフォーマット変換が行われます。
入力 - 変換 - Validation - 変換 - メイン処理 - 変換 - 結果出力 - 後処理 - レスポンス
という形になります。
変換はミドルウエアやフレームワークが自動的に行う場合もあれば、プログラムの中で手動で行う場合があります。例えばWebアプリケーションの場合、HTTPのリクエストは、アプリケーションサーバが、HttpServletRequestオブジェクトに変換します。Strutsなどのフレームワークを使っている場合は、ActionFormに自動的に変換されます。出力をDBに行う場合、ORマッピングツールを使っている場合、ORマッピングツールがSQLに自動変換します。変換の手間はツールを使うと減ります。
Validationは、処理を行うにふさわしい入力ではない場合、エラーとしてはじく機能です。こうすると処理を行っている最中にエラーを出したり、間違った結果を出してしまったりすることを防ぐことができます。Validationはアプリケーションに対する入力出力のレベルで用いられることもあれば、個々のメソッドでも用いられる場合もあります。メソッドの処理にふさわしくない引数をはじきます。
アプリケーション全体で見た場合、各処理は分割して行われます。分割することによって、各処理の責務をはっきりさせ、メンテナンスもしやすくなります。
いろいろな考え方があるのですが、基本はMVCです。
MVCとは、Model、View、Controlに責務を分割するという考えで、Modelがメインの処理を受け持ち、Viewは画面出力を表し、Controlは入力をどのModelに振り分けるかという制御の役割を持ちます。
この考え方のメインとなっているのは、ModelとViewの分離です。分離していれば、UIのデザインを変えるなどを変更しても、Modelを変更する必要がありません。
この分割の仕方は、アーキテクチャーパターンとしてまとめられています。
MVC(Model - View - Controller) BCE(Boundary - Control - Entity) PDD(Presentation - Domain - DataSource) PAC(Presentation - Control - Abstraction) PAD (Presentation - Application Logic - Domain) J2EE (JSP - Servlet - Business Delegate - Session Facade - Business Logic - EntityBean)
プレゼンテーション層: 外部インターフェース バウンダリー ビュー ビジネス層: ドメイン モデル コントローラ アプリケーション ビジネスロジック データ層: エンティティ データソース パーシステンス
分割し、各レイヤー間は疎結合にします。インターフェースでのみ接続するようにし、その先の実装については意識しないようにします。こうすることで変更が他レイヤーに影響しないようにします。
ここからはWebアプリケーションに話を絞りたいと思います。
strutsの場合
(ブラウザ) - JSP - Validation - ActionServlet - Action - Service - DAO - (DB)ViewはJSPが担当し、ValidationはActionFormのvalidate()メソッド、全体のコントローラはActionServletが行い、各Pathに対するコントローラはActionが行い、Serviceがロジックを担当し、DAO(Data Access Object)がデータベースへのアクセスを担当します。
Actionはスレッドセーフではないため、シングルインスタンスのため、インスタンス変数を使うことはできません。インスタンス変数を使えないのは、メソッドを分割した際の、引数と返り値のやり取りで、厄介になります。StrutsのActionはコントローラであり、個々の状態を持つべきではありません。後段のレイヤーで必要であれば状態を持たせます。
基本的には後段にはアプリケーションサーバ依存のRequestやResponse、StrutsコントロールコードとなるMappingやForwardは渡さないようにします。必要な場合は、別のオブジェクトに値を詰め替えて送ります。
DBへのアクセスは、DAO層に集中させ、ロジックはサービス層に置きます。
処理をどのレイヤーに持ってくるかという判断は難しいときがあります。あるべき論で配置するケースと処理のしやすさでするケースがあります。ViewとModelは分離できても、コントローラとロジックとデータアクセスの分離は難しいときがあります。実際のところロジックはSQLで処理されている場合、論理的な意味でロジックとデータアクセスは分離できず、DBへのアクセス中心かどうかで分けることになります。
PresentationもJavascriptはとなると、これはロジックにも見えます。ValidationもActionの前に分離したつもりでも、DBアクセスが必要なValidationはAction以降で行う必要があります。ActionForm内に置くのは望ましくありません。
結局どう切るかによりますが、何をしているかよりもどう接しているかの方がいいでしょう。制御とロジックを厳密に分けることは難しいです。なので、PresentationとDBアクセスを省いた残りがコントローラとロジックになります。
各レイヤに配置されるのは単一のクラスではありません。機能に応じて、クラスは分離されます。
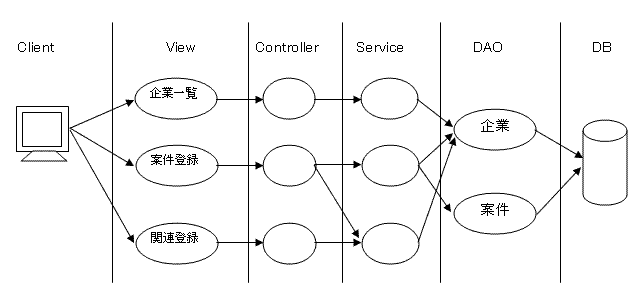
このように縦にはレイヤーわけがなされ、横には各機能で分割されます。しばしば前段の別々のクラスが後段の同じクラスを利用することもあります。
各レイヤー間でデータを明け渡しする場合、以下のようなデータオブジェクトが使われます。
画面(出力)でのオブジェクト 画面(入力)でのオブジェクト 受け渡し用のオブジェクト(DTO) 永続エンティティ(DBに対応) 中間エンティティ
種類としては以上のように分類されますが、共通している部分が多いので一緒にしたりします。全部別々にすると、一つフィールドを増やすたびに、全クラスを変更しなければならないという手間がかかります。
Strutsの場合、入力オブジェクトとしてActionFormが用意されています。これを出力用にも用いたり、後段のレイヤーにそのまま渡したりするのは賛否両論ありますが、プロジェクトの規模や、各レイヤーで担当者を変えているのか、機能ごとに担当者を分けて、一人で全レイヤーを行うのかによって違ってきます。
別々にする場合、ActionFormをDTOに詰め替える作業を行います。さらにDTOをORマッピングで使うエンティティクラスに詰め替える作業をしたりします。間にあるロジックが厚い場合はこれも必要かもしれませんが、ほとんどロジックがない場合、実に無駄な作業です。BeanUtilsのcopyProperty()メソッドを使えば簡単にできる場合もありますが、構造が違う場合手動での詰め替えが必要になります。
意味的に綺麗に分類しようとすると、余計な作業が発生しますので利点ばかりではありません。分類と共通化が衝突する一例です。
モデルとは、アプリケーションの持っている論理的・静的な構造を言います。基本的に正規化・最適化され再利用可能な普遍の構造にします。
永続的エンティティは、データベースのテーブルとイコールの場合もありますが、データベースは性能やメンテナンスを考えて別の構造をとる場合があります。
しかし、通常業務アプリケーションの場合、データベースとドメインはイコールであり、ER図を見ればそのアプリケーションが何を行なっているか分かります。ここはDOAが重視する点です。純粋なDOAの場合、モデル=DBであり、クライアントとの間にあるのはコントローラに過ぎず、構造化の必要はありません。一方、オブジェクト指向ではモデル/ドメインを重視しデータベースは単なるストレージとみなされます。
ドメインを重視するのは、開発の基本ですが、思想によって扱いが変わってきます。(cf. データ中心指向とオブジェクト指向)
パフォーマンスの問題を理由に、よくJavascriptやストアドプロシージャが使われます。
JavascriptはValidationでよく使われます。というのは、いくらブロードバンドとはいえ、入力ミスが合った場合、サーバ側でのみValidationをしているとユーザはその間待たされた挙句再度入力を要求されることになるからです。そのため、簡単なValidationはフォームの送信前にブラウザ上で行うことになります。
これだけならまだいいのですが、Javascriptは多彩なことができます。テキストボックスに入力した数値を元に、サーバに問い合わせることなく計算結果を表示したり、プルダウンから何かを選択したときにそれに応じてフォームを変えたりとかいろいろできます。近年はAJAXの流行からさらにJavascriptでのプログラミングが増大しています。
こうなると、レイヤー分けが綺麗には行かなくなり、ロジックが分散することになります。
それはストアドプロシージャについても同じで、DB側でプログラムを組んでしまうので、ロジックがDB側に移行することになります。
きちんとポリシーを決めて設計していればいいのですが、そうではないとあちこちにロジックが分散して、メンテナンスが非常に難しくなります。
サーバサイドの技術であるJ2EEでは、アーキテクチャーについて、いろいろと考慮がなされています。
Javaによるオブジェクト指向では、再利用可能なコンポーネントとしてJavaBeanを定義しています。アプリケーションサーバ上で動くEnterprise JavaBean(EJB)は、疎結合、依存性管理、ライフサイクル管理、宣言的なサービス、移植性、スケーラビリティ、信頼性をうたいました。
EJBの呼び出しにはJNDIが使用され、インターフェース経由でEJBにアクセスし、直接はアクセスしない構造をとっています。そのため、メソッドへのアクセスがアプリケーションサーバによってインターセプトされ、トランザクションやセキュリティ、永続化、リモート呼び出しなどといったことを外付けで規定できるようになりました。つまりEJBオブジェクトがクライアントとBeanの間に割って入り、これらの機能を実現します。そのため、トランザクションの境界をBeanの中で設定しなくても、外側のXMLファイルの中で設定することによって、管理できるようになりました。
宣言的とは、処理を記述するのとは相対する概念です。処理というのは、一つ一つ順に何かを行っていくものです。宣言とは、あるものについて、これが何であるかを述べるだけです。例えば、設定ファイルの中にトランザクションについて宣言しておけば、自動的にトランザクションを開始し、メソッドの終了時にはコミットあるいはロールバックをしてトランザクションを終了してくれるわけです。
プログラミングの進化とは、順接処理からの脱却なのかもしれません。初期のプログラムは上から下に処理が流れるべた書き。それが制御文で流れを変え、関数で処理を一言で表現し、オブジェクトの導入でさらに処理を抽象化しました。GUIのイベントドリブンは、単一の処理の流れを分断しました。関数型言語も、順に流れる処理とは違います。
将来的には、処理を書かずに、宣言の集まりでプログラムができるかもしれません。
EJBは先にあげた利点の反面、複雑さやアプリケーションサーバ上でしか動かない使いにくさ、性能上の問題などもあり、DIコンテナと呼ばれる軽量型のコンテナに取って代わりつつあります。EJBで実現できていたことは、DI+AOPを使うことで実現できます。リモートからのアクセスもRMIで実現します。
また、AOPはアスペクト指向と呼ばれ、横断的関心ごとを解決するソリューションと考えられています。横断的とは、別々のオブジェクトの間で共通の関心事を指し、ソースコードを変えることなく、メソッドに機能を追加できます。実際にやっていることはEJBオブジェクトと同じように、メソッドの開始と終了時に割り込んで、インターセプタが処理を行なうことで、使われていることもEJBで行なっていたようなトランザクション管理やセキュリティなど、またロギングなどにも使われます。確かにこれらの各メソッドに共通するような機能を括りだし、ソースコードから排除してしまうのは素晴らしいことで、ソースコードがかなり綺麗になります。
DIはDependency Injection(依存性注入)という意味で、SpringFrameworkやSeasarなどの流行もあって、Webアプリケーションではこの考え方が主流になってきているように思います。
例えば、AというオブジェクトがBというオブジェクトを使っているとき、AはBに依存している、といいます。通常、アプリケーションは一つのオブジェクトだけで完結するわけではないので、当然依存性は発生します。では依存性を注入するとはどういうことでしょうか。
AとBが密に結合している場合は、AはBのことを知っています。
class A {
...
B b = new B();
...
}
しかしこれでは密に結びつきすぎです。そこで、Factoryの導入です。Bはインターフェースにして、Factoryで具象クラスBImplを生成します。これによってAが直接Bの実装に依存することはなくなります。
class A {
...
B b = BFactory.create();
...
}
class BImpl implements B {
...
}
class BFactory {
...
B create() {
return new BImpl();
}
...
}
一つ一つFactoryを作るのは大変なので、BeanFactoryでインスタンスを管理して、lookupする形をとります。EJBではJNDIを使いContextからlookupしてサービスを取得しますね。
class A {
...
B b = (B)BeanFactory.lookup("B");
...
}
これはDependency Lookupです。これによってソースコードから具象クラスの指定を排除することができました。Bの実装ラスを変えたい場合は設定ファイルを書き換えれば済みます。しかし、これでもクラスAは依存先を自分で呼び出しているわけです。呼び出さないといけないのです。そこで依存性注入です。
class A {
B b;
public void setB(B b) {
this.b = b;
}
}
AはBの実装のことをまったく知らないし、自分でBをセットすることもしません。外からセットされるのを待っているだけです。クライアントが直接セットするか、コンテナがBをセットし、Aのインスタンスをプールしておきます。Aはコンテナのことを全く知りません。
Aのクライアントは、Aのインスタンスをコンテナからlookupして取り出します。クライアントについてはDIは使えません。クライアントはコンテナのことを知り、コンテナからAを取り出す必要があります。
これの何がよいのかというと、AはBの具象クラスにも、コンテナにも依存していないところです。単なるありきたりのクラス、POJOですが、POJOであるために依存性がなく使いやすいのです。必要であれば、コンテナなしに、クライアントがAに依存性を注入することもできます。
EJBとの違いは、EJBではSessionBeanなどの特別なインターフェースを実装する必要がありましたし、それ以外にもHomeInterfaceなどいろいろ用意する必要がありました。ところが、DIを使うと、POJOだけで実現でき、コンテナはアプリケーションサーバと比べて軽量なので、動作させるのも簡単です。ということで開発効率が上っています。
Aだけのテストをする場合、Bの実装ができあがっていないときでも、Bのインターフェースを実装したモックを作って、モックを注入すればテストも容易にできます。
EJB3になってからは、DIの概念が全面的に取り入れられ、簡単にEJBを扱えるようになりました。さらにJava5.0で導入されたアノテーションを使って、これまでXMLに記述していた内容をBeanのソースに記述できるようになり、外部ファイルであるXMLファイルを参照しなくてもBeanがどのような役割を持っているのかについて理解しやすくなりました。
アノテーションの使用には賛否両論があります。ソースコードの中にあるので理解しやすくなるものの、動作を変えるにはソースコードをいじらなければならないことになります。XMLに記述していれば、ソースコードをいじることなく動作を変えられます。
アノテーションの面白いところは、ソースコードに記述されたコメントに過ぎず、そのクラス自体は何も変化しないことです。そのクラスを使う側が、そのクラスをどう扱うかの参考にするのです。そのクラスをStateful SessionBeanとして扱うのか、Stateless Session Beanとして扱うのか、Entityとして扱うのか、トランザクションはどうするのかなど。これらはすべてそのクラスの動作というよりも外部で規定できることです。
最近、Railsの流行もあってか、COC(Convention Over Configuration)やConfiguration By Exceptionという概念がよく聞かれます。COCは設定より規約ということで、規約に従ってクラス名や変数名を設定すると、自動的にフレームワーク側で処理してくれるというもので、それによって多くのコード量を減らすことに成功しています。
この考えは、Default値を使うという使い古された思想にすぎないのですが、これまでは設定値などにおいてはよく使われていましたが、コンポーネント間の接続には使われていませんでした。
Strutsの設定ファイルを見ると、マッピングの嵐です。URLのPathとActionをマップする部分、遷移先の論理名とJSPのマッピングの部分など。
これまでは、依存させないために、マッピングを間に挟むというのが、常識になっていました。Railsでは、こういうところで設定を必須とせず、デフォルトでPathの名前がそのままControllerのクラス、メソッドになっています。
これは、ある意味、柔軟性を失って、疎結合を失い、依存性を増大させているように見えます。しかし、これはあくまでもデフォルト値なので変えたければ設定でオーバーライドさせることができます。
つまり、時代は、密に結合している状態から、疎結合、そしてCOCへと進んでいるといえるでしょう。



