一つ上へ
ホーム ざれごと ワシントン州 ツール NT豆知識 Win32プログラミングノート 私的用語 ジョーク いろいろ ゲーム雑記 Favorites 掲示板 Mail
IA-64に関するお勉強メモ。間違ってても責任は持てん。でも何か気がついたらメールで教えてください。
このお勉強ノートのGoalは、一般的な、純粋に論理を扱うプログラムのディスアセンブリが読めること。 入出力やメモリマネージメント(ヒープじゃなくて、メモリマッピングなどのこと、念のため)・コンテクストスイッチングなどCPUべったりのOS的オペレーション、マルティメディア系のパラレル演算や、 浮動小数点演算な どは積極的には扱わない。
また、ia64系プロセッサの概論や特徴などは、ニュースサイトをはじめとして解説系まで他にいくらでもWebサイトがあるので、ここでは省略する。
また、コンパイラライタが知っているべき事項で、デバッガでディスアセンブリを追っかけるためにはあまり必要のない、あるいは無視しても大差ないと思われるものについても、詳細な記述は省略する方針。 いずれにせよ、コンパイラを書こうと思ったら、Intelから提供される一次資料にあたるべきである。 こんなページを見ている暇があったら、pdfをダウンロードするなり、紙媒体を購入するなりして、マニュアルと首っ引きで勉強するほうが良い。
アプリケーション・レジスタ・セットを以下に。 ia64kd の表記による(括弧内はIntelの表記)。
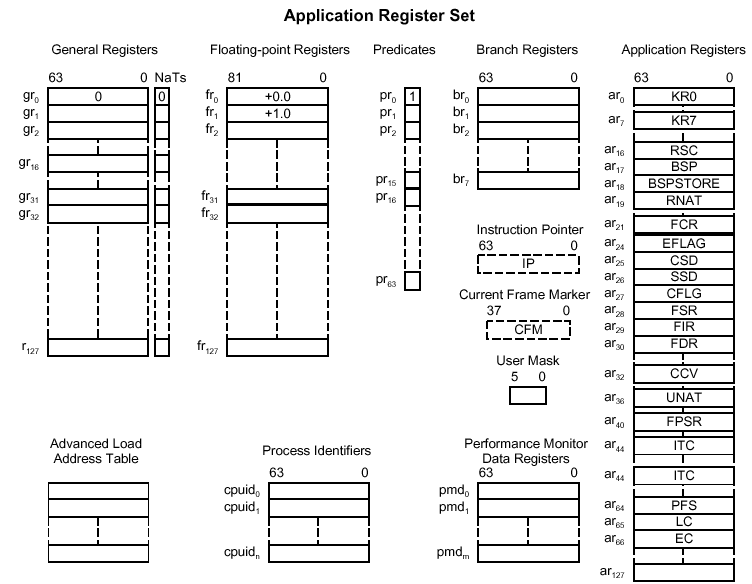
r0〜r127まで、128本。次のように分かれている
|
r0〜r31 |
スタティック 汎用レジスタ
|
|
r32〜r127 |
スタック 汎用レジスタ
|
r0〜r31のレジスタに用途が固定されているものがある。 r0 のようにハードウェアで用途が固定されているものと、r1 のように NT 環境で用途が決められ固定されているものとある。
|
r0 |
ゼロレジスタ (ハードウェアによる)。
|
|
グローバル ポインタ。r1 が割り当てられている。
* 正確に言うと、アドレッシングモードはオフセットなしのレジスタ・インダイレクトしかないが、アドレスを計算すべく用いられる addl 命令のオペランドが 4MB 分 22ビットしかない、ということ。
| |
|
ret0〜ret3
|
関数の戻り値用。r8〜r11 が割り当てられている。
|
|
sp
|
スタックポインタ。r12 が割り当てられている。
|
|
r13 |
TEB (Thread Environment Block)のアドレス。 |
r4〜r7 は保存されることになっている。r13 には手を触れてはならない。 gp は、違うモジュールへ移るごとに設定しなおされる(というか、コンパイラはそのようなコードを生成しなければならない)。
その他のレジスタは、一時的用途に使ってよい。
整数レジスタには、それぞれに対応した NaT (Not a Thing) 1ビットレジスタがある。 スペキュレイティブ実行(投機実行)において、レジスタの値が有効であるかどうかの確認に使われる。
戻り値レジスタはなぜか4つもある。なぜ?
組み合わせれば、256ビット(=32バイト)までのデータを返せる。小さ目の構造体を値として戻しても(多分)OKなわけだ。
浮動小数点レジスタについては省略。
プレディケイト "predicate" を辞書で引くと、「述語」という訳が最初に載っている。
ia64では、それぞれの命令の前について命令を修飾し、条件実行が可能になっている。
例えば、次の命令では、
(p15) add r34 = r32, r33
p15 がTRUEの時に限り、r34 に r32 と r33 を加算した値を代入しろ、という意味。
p15 が FALSE だったら、r34 の値に変化はない。というか、この命令は実行されない。
プレディケイト レジスタを使った条件実行では、パイプラインを乱す分岐が必要ないので、パフォーマンス上とっても有利。
しかし、アセンブラを読むほうはちょっと辛い。
が、今までのところ、コンパイラの吐くプレディケイト・レジスタを使った条件実行は、割とシンプルなものに限られているようで救われている。
実は、ほぼ全ての命令にはプレディケイト・レジスタを指定出来る。 と言うか、しなくてはならない。 常に実行される命令には、ディスアセンブリには表示されないが、pr0 がプレディケイト・レジスタとして指定されているわけ。 pr0 は読み込み専用のプレディケイト・レジスタで、常に1である。
プレディケイト・レジスタは、主に比較命令でセットされる。
|
pr0 |
読み出すときは常に TRUE。
|
|
pr1〜pr15 |
スタティック プレディケイト レジスタ
|
|
pr16〜pr63 |
ローテート プレディケイト レジスタ |
NTでは、pr6〜pr15 は一時的用途に用いてよい。 他のプレディケイト・レジスタは、予約されている。
64個のプレディケイト・レジスタをまとめて扱うため、pred という仮想レジスタがある。
直接ジャンプ以外の、間接ジャンプや飛び先を計算してのジャンプなどは(関数コールもジャンプの一種)、ブランチ・レジスタを使う。 なんでも、そのほうが CPU にとって都合が良いんだそうだ。 で、間接ジャンプは、まず br レジスタにジャンプ先アドレスをセットしてから行われる。 全てのモジュール外コールは、br レジスタを使った間接ジャンプになる(と思う)。 ia32だったら、直接 call [memory] なんて出来て便利だったのにね。 逆アセンブルリストをデバッガで見ても、レジスタ参照ジャンプなのでさっぱり分からん。 少なくとも直感的ではないわなぁ。
|
br |
リターン・アドレス (b0)
|
|
b1〜b5 |
関数間で保持されていなければならない
|
|
b6〜b7 |
一時的利用可 |
詳しいことは、後述のブランチ命令を参照。
特殊レジスタ。 ループカウンタ LC や、ia-32 エミュレーション用レジスタなどがある。
|
レジスタ |
名前 |
説明
|
|
ar0〜7 |
kr0〜7 |
カーネルレジスタ0〜7
|
|
ar8〜15 |
|
予約
|
|
ar16 |
rsc |
レジスタ・スタック・コンフィグレーション・レジスタ
|
|
ar17 |
bsp |
バッキング・ストア・ポインタ
|
|
ar18 |
bspstore |
メモリ・ストアのためのバッキング・ストア・ポインタ
|
|
ar19 |
rnat |
RSE NAT コレクション・レジスタ
|
|
ar20 |
|
予約
|
|
ar21 |
FCR |
ia-32 浮動小数点コントロール・レジスタ
|
|
ar22〜ar63 |
|
省略
|
|
ar64 |
pfs |
Previous Function State
|
|
ar65 |
lc |
ループ・カウント・レジスタ
|
|
ar66 |
ec |
エピローグ・カウント・レジスタ
|
|
ar67〜ar127 |
|
省略 |
ユーザ・マスク・レジスタは、プロセッサ・ステータス・レジスタのサブセットで、ia64アプリケーションからアクセス出来る。 ユーザ・マスクは、メモリアクセスのアラインメントや、バイト・オーダなどをコントロールする。
5 |
4 |
3 |
2 |
1 |
0 |
mfh | mfl | ac | up | be | rv |
|
rv |
reserved
|
|
be |
ia64 ビッグ・エンディアンメモリアクセス
ia32のエミュレーションでは、このビットに依らず常にリトル・エンディアンになる。
|
|
up |
ユーザ・パフォーマンス・モニタ
|
|
ac |
アラインメントチェック
|
|
mfl |
下位(f2〜f31) 浮動小数点レジスタが変更されたとき1
|
|
mfh |
上位(f32〜f127) 浮動小数点レジスタが変更されたとき1 |
ia64はVLIW (Very Long Instruction Word)なCPUで、通常3つの命令が128ビットのフィールドにパックされている。 これがバンドル。 それぞれの命令が収まる場所は、スロットと呼ばれる。各々41ビット。

iip が指すアドレスはバンドル単位ということだが、バンドルが並列実行の単位かというと、そうではない。
バンドル中に配置できる命令のパターンには制約があり、「テンプレート」と呼ばれる5ビットのフィールドで指示される。 5ビットだから、最大32個のパターンが存在することになる(予約されているパターンがあるので、現時点で32種類あるわけではない)。
テンプレートの中には、「ストップ」と呼ばれる並列実行の区切りを持つものがある(持たないものもある)。 VLIWの弱点に、将来語長が変わった場合のソフトウェアの非互換があるのだが、テンプレート中にストップを持つことで、ia64は将来への互換性を保持している、ということか。
ただでさえバンドル中の組み合わせに制約があるうえ、ストップまで視野に入れてコードを生成しなければならないコンパイラの負担が増えるわけだ。 つまり、ia64のスピードは、コンパイラのコード生成にかかっている。 というか、ia64ははっきりとそれを前提としている。 後で触れるが、データの先読みなどもコンパイラが指示するのである。
ia64kdでは、ストップはインストラクションの後の ";;" で示される。
r32〜r127 の汎用整数レジスタは、レジスタ・スタックとして使われる。 関数の呼び出し時と終了時に、レジスタ・リネーミングにより、レジスタ・ファイルからレジスタが割り当てられる。 どのくらいレジスタを使うかは、普通関数の頭で宣言する。 割り当てられたレジスタ以外のレジスタにはアクセスできず、Illegal Operation faultが発生する。
レジスタ・ファイルに収まらなくなったら、実メモリ上にあるスタックへ内容が退避される。 ここらへんの処理は、CPU が勝手に、かつ効率的に行う(はずである)から、今は深入りしない。
スタックとして使われるレジスタには、ローカルとアウトプットという、2つの領域がある。 ローカルとは、関数の引数と、ローカル変数のエリア。 アウトプットは、その関数からさらに呼び出す関数の引数のためのエリア。
次の例では、引数 4つとローカル変数10個を持つ関数 A と、引数を2つとりローカル変数15個を使う関数 B を考える。 関数 A から呼び出す関数のうち、最も多い引数をとる呼び出しでは7個の引数を取る。 関数 B からでは3つとする。 簡単のため、引数は全てレジスタスタックに積まれるものとする。
void A(int a, int b, int c, int d)
{
int i1, i2, i3, ... // 合計10個
B(i1, i2);
}
void B(int a, int b)
{
int i1, i2, i3, ... // 合計15個
}
この条件のもと、関数 A から関数 B を呼び出すときのレジスタスタックの様子を追ってみる。
|
|
関数Aのローカル |
関数Aのアウトプット
|
関数Bのアウトプット
|
|
関数Aの実行中 |
r32〜r45
|
r46〜r52
|
|
|
関数Bを呼び出した直後 (引数が2つとしましょう) |
|
r32〜r38
|
|
|
関数Bの頭でalloc |
|
r32〜r47
|
r48〜r50
|
|
関数Bからリターン |
r32〜r45
|
r46〜r52
|
|
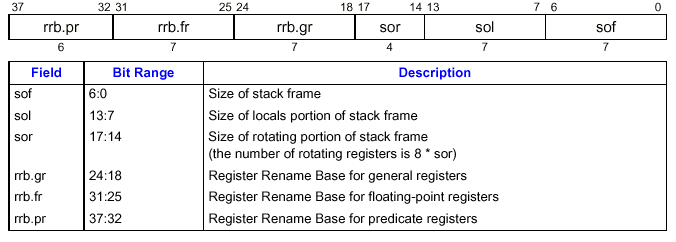
現在の関数のフレームは CFM に、一つ前のフレームは PFM に記憶されている。 CPU にとっては、引数とローカル変数の区別はないので、レジスタ・スタックは sol と sof という2つのフィールドで管理されている。 sol は、ローカルの大きさ。ローカルの大きさは、引数の数とローカル変数の数に等しい。 sof はローカル+アウトプットの大きさ。sof は、現在見えるレジスタの数に等しい。 アウトプット(関数内から呼び出す関数の引数の最大数)は、sof-solになる。
レジスタスタックのサイズには限りがあるから、当然メモリ上に退避用の領域が用意されている。 bsp レジスタで、現在の r32 の場所が示される。 デバッガに落ちてきたときには、レジスタファイルはメモリにダンプされているはず(bspstore)。
レジスタスタックと別に用意されている、旧来の意味でのスタックは、sp レジスタにより示される。 ローカル変数が大きいとき(でっかい配列を取ったときなど)は、コンパイラはレジスタスタックに加えてメモリ上のスタックも割り付ける。 メモリ上のスタックはソフトウェアによるもので、CPUとしては直接サポートしていない。
alloc というインストラクションで、現在のレジスタ・スタックフレームの大きさを変更する。 普通は関数の頭で alloc を行う。
alloc r1 = ar.pfs, i, l, o, r
呼び出し側の関数のファンクション・ステート・レジスタ(pfs)が、r1 に保存される。 r1 は、新しいフレームでの指定になる。
i は引数レジスタの数。 l は、ローカル変数の数。
o は、アウトプットレジスタの数。
r は、ローテートの数。まだ使っているのを見たことがない。
CPUにとっては引数もローカル変数も区別はないので、逆アセンブルすると、l は常に0で、i + l が i として表示される。
他に、flushrs などという命令があって、レジスタスタックをメモリへセーブするらしい。 おそらく、コンテクストスイッチングの時に使われるんでしょう(というようなことがIntelのマニュアルに書いてある)。
バッキングストアとは、CPU内のレジスタファイルが足りなくなったときに、メモリ上へレジスタをセーブしておく領域。
実装依存だが、CPUは複数のキャッシュレベルを有効活用するはずで、毎回メモリへの書き出しが発生するわけではない、と思う。
いずれにせよ、深い再帰や複雑な関数コールなどでは、簡単にレジスタファイルを使いきってしまうと思われる(レジスタの利用効率も現段階ではあまり良いとも思えない)。
バッキングストアは、bspによりポイントされる。
スタックポインタは、従来の意味でのソフトウェアスタックポインタに近い。 メモリ上のアドレスを指し、レジスタファイルを援用することになるだろう。 ただし、CPUのアーキテクチャから固定されたレジスタがspなわけではなく、あくまでも環境による規約に過ぎない。 NTの規約では、r12がスタックポインタに割り当てられている。
バッキングストアはメモリの上位に向かって伸びる。 r12を使ったソフトウェアスタックポインタは、メモリの下位に向かって伸びる。 両ポインタは、KTHREAD構造体のStackBaseをはさんで、メモリの上位と下位という反対の方向へ伸びることになる。 ということで、事実上二つのスタックがオーバラップすることはない。
加算(add)と減算(sub)には、2つの入力を取るものと、3つのものとがある。 3つのものは、最後の引数に "1" を指定することで区別する。 結果は、r2 + r3 + 1 になる。 なんの役に立つのか、まだよく分からない。 インクリメントなら、即値の加算を使えばいいわけだし…。
即値は14ビットで、1つ目のレジスタの代わりに指定する。 加算では22ビットの即値を取ることも出来るが、その場合他のレジスタはr0〜3に限られる。 いずれも、符号拡張される。
add r1 = r2, r3 add r1 = r2, r3, 1 adds r1 = imm14, r3 addl r1 = imm22, r3
subも似たようなものだが、即値が8ビット定数に限られる。
「シフトレフト アンド Add」命令(shladd)は、レジスタを左に1〜4ビットシフトして、2つ目のレジスタと加算する。 x86 でいうと、スケールつきの LEA (load effective address) のようなものですな。
shladd r1 = r2, n, r3 → r1 = (r2 shl n) + r3
え〜、ちなみに、キャリーの保存先とか、キャリーつきの加算がないような気がするんですが…。 多倍長演算はどうするんでしょう。 キャリーの代わりに、比較を使う?
論理演算には、and、or、xor と andcm がある。 andcm は、レジスタまたは即値と、もう一方のレジスタを反転した値との AND を取る。
32ビットアドレスの計算に、addp と shladdp がある。詳細は省略。
64ビット未満の整数を64ビット整数へ変換する命令に、sxt と zxt がある。 sxt は符号拡張するが、zxt はゼロ・エクステンド。 レジスタ中の8ビット、16ビット、32ビット整数を、64ビット整数へ変換する。
|
shr |
右へ算術シフト(signed)
|
|
shr.u |
右へ論理シフト(unsigned)
|
|
shl |
左へシフト
|
|
extr |
Extract signed (右へ算術シフトしてマスクをかける)
|
|
extr.u |
Extract unsigned (右へ論理シフトしてマスクをかける)
|
|
dep |
Deposit (左へシフトしてマスクをかけ、マージ)
|
|
dep.z |
Deposit in zeros (左へシフトしてマスクをかける)
|
|
shrp |
Shift right pair
|
レジスタに定数を代入するとき、小さな値(高々22ビットまで)なら、add や or を使って r0 との演算ですむ。 大きな定数は、専用の命令がある。
|
mov |
22ビットの即値を代入
|
|
movl |
64ビットの即値を代入 |
上記の mov は、実際には add, ra = Imm22, r0 のalias。
movl は、64ビットの定数をオペランドに持ち、同じバンドル中のスロットを2つ消費する唯一の命令。
比較演算の結果は、プレディケイト・レジスタへ格納される。 ia64の殆どの命令は、プレディケイト・レジスタによって修飾可能で、指定されたプレディケイト・レジスタの真・偽によって条件実行される。
p0 は、ハードウェアによって真に固定されている。
条件実行不可な ia64 命令がいくつかある。 スタックフレーム・アロケーション(alloc), rrbのクリア(clrrrb)、レジスタ・スタックのフラッシュ(flushrc)、カウンテッド・ブランチ(cloop, ctop, cexit)。
比較演算は、結構ややこしい。 Cなど高級言語の、連続する複雑な論理演算を、多分効率的に実行出来るだろうが。
比較命令は、
というフォーマット。比較対象には、レジスタまたは8ビットの即値が指定できる。
crel は、下記の「比較関係」を参照。これは難しくも新しくもない。 しかし、ctype は、ちょっとややこしい。
一番簡単なケースは、次のようなもの。
cmp.eq p6, p7 = r32, r33
r32 と r33 を比較する。値が等しければ、p6 には1が、p7 には0がセットされる。 等しくなければ、p6 には0が、p7 には1がセットされる。
次に簡単なのが、アンコンディショナル・ケース。次のようになる。
(p6) cmp.eq.unc p8, p9 = r32, r33
プレディケイトされて、かつ unc がついているところに注意。
もし p6 が真なら、通常の cmp と動きは同じ。
だが、もし p6 が偽なら、p8 と p9 の両方に偽がセットされる。
プレディケイトレジスタが偽でも、インストラクションがなにがしかの意味を持つ、非常に稀なケース(普通はインストラクションが無視される)。
とうとう「並列比較(parallel comparisons)」までやってきた。 Cでいう、論理演算(ショートカットつき)のアセンブリ版、みたいなもの。
cmp.eq.and p6, p7 = r32, r33
これをCで書くと、
p6 = p6 && (r32 == r33)
p7 = p7 && (r32 == r33)
以前の比較が真で、r32 と r33 が異なる場合にのみ、両方のプレディケイト・レジスタは偽にセットされる。 それ以外の場合、プレディケイト・レジスタの値は変化しない。
cmp.eq.or p6, p7 = r32, r33
これは、Cでいう論理ORになる。
p6 = p6 || (r32 == r33)
p7 = p7 || (r32 == r33)
cmp.eq.orcm p6, p7 = r32, r33
cm とは、complements のこと。
p6 = p6 || !(r32 == r33)
p7 = p7 || !(r32 == r33)
ド・モルガンの演算…
cmp.eq.or.andcm p6, p7 = r32, r33
p6 = p6 || (r32 == r33) p7 = p7 && !(r32 == r33)cmp.eq.and.orcm p6, p7 = r32, r33
p6 = p6 && (r32 == r33) p7 = p7 || !(r32 == r33)
実は、andcm や orcm, and.orcm は仮想オペコードで、NOTビットを立てた and, or, or.andcm のコードが生成される。
|
cmp.crel.ctype
|
cmp は64ビットの比較、cmp4 は32ビットの比較。
|
ノーマル、アンコンディショナル、and, or, ド・モルガン
|
|
tbit.trel.ctype |
ビットテスト
|
ノーマル、アンコンディショナル |
他にもあるけど省略。
|
符号付
|
符号なし
|
投機実行を指定するものも含めて数は多いが、アドレッシングモードは少ない。
というか、オフセットなしのレジスタ・インダイレクトしかない。
lea もない(ついでに言うと、整数に対する乗除算命令もない)。
ポスト・インクリメントとポスト・デクリメントはある(どっちも同じオペコードで、オペランドが符号付なだけ)。
|
ld |
Load
|
|
ld.s |
Speculative load
|
|
ld.a |
Advanced load
|
|
ld.sa |
Speculative advanced load
|
|
ld.c.nc |
Check load
|
|
ld.c.clr.acq |
Ordered check load
|
|
ld.acq |
Ordered load
|
|
ld.bias |
Biased load
|
|
ld8.fill |
Fill
|
|
st |
Store
|
|
st.rel |
Ordered store
|
|
st.spill |
Spill
|
|
cmpxchg |
Compare and exchange
|
|
xchg |
Exchange memory and GR
|
|
fetchadd |
Fetch and add |
※ このお勉強ノートでは、全部はカバーしてません
ld 命令が、メモリから汎用レジスタへロードするために使われる。 アドレッシングモードは、オフセットなしのレジスタ・インダイレクトの一種類のみ。
sz は、1, 2, 4, 8 のいずれか。読み取るバイト数を指定する。 バイト数が8に満たない場合、残りの上位ビットはゼロ・エクステンドされる。 ldtype についての詳細は、後述の投機的メモリアクセスを参照。 ldhint については、後述のキャッシュ階層コントロールとヒントを参照。
1, 2, 4, 8バイトのデータをメモリに書き込める。 ポストインクリメント・デクリメント出来るが、即値のみ。 投機的実行は出来ない。
アトミックなセマフォ操作には、エクスチェンジ(xchg)、コンペア・アンド・エクスチェンジ(cmpxchg)、フェッチ・アンド・アッド(fetchadd)がある。
|
xchgsz
|
r1 = [r2], r3
|
|
cmpxchgsz |
r1 = [r2], r3, ar.ccv
|
|
fetchaddsz |
r1 = [r2], r3 (または即値)
|
NTで使われているコンパイラ・リンカは、データに対するリージョンを、スモールデータとラージデータの2つに分割している。 スモールデータリージョンとは、gp に対する1回の間接アクセスでアクセス出来る領域。 スモールデータリージョン内のデータへのアクセスは、次のようになる。
addl r31 = data_a, gp ;;
ld r31 = [r31]
data_a ってのが gp からのオフセット。
対して、ラージデータには、2段階の間接アクセスが必要となる。
ラージデータリージョン内のデータのアドレスは、gp から直接は得られない(4MBの壁がある)ため、スモールデータリージョンにポインタを用意し、そのポインタをアクセスするという形になる。
addl r31 = data_b_ptr, gp ;;
ld r31 = [r31] ;;
ld r31 = [r31]
アクセスするのが構造体で、オフセットの計算が必要なら、さらに:
addl r31 = data_b_ptr, gp ;;
ld r31 = [r31] ;;
add r31 = 8, r31 ;;
ld r31 = [r31]
とでもなろう。いやはや、なんとも面倒くさいものだ。
そいで、実際にはこの一連のレジスタ操作が、あちこちに散らばるんだよな…。
ld.s 命令は、データの先読みを CPU に指示する(なお、st.s はない)。
理論的には、CPU は ld.s が実行された時点ですぐにメモリから値をロードする必要はない。 実際に必要になるまでに間に合わせてメモリから値を読み取ればいいので、キャッシュにそのデータがなかったからと言って、パイプラインを止めてキャッシュラインがフィルされるまで待たなくて良い。 代わりに、メモリアクセスの要求を出すだけ出して、裏でレジスタの値をゆっくり読み取ればよいわけだ。
ld.s は通常の ld に似ているが、アクセス例外の発生を先送りする。代わりに、NaT ビットをセットする。 chk.s で NaT ビットをチェックでき、その場合もう一度投機的でないメモリ読み込みを実行するロジックへジャンプしたりするわけ。 なお、そこでは当然例外が発生することになるだろう。
一般的に、汎用レジスタまたは浮動小数点レジスタに結果を格納する命令は投機実行可能で、投機的メモリ読み込みの結果 NaT の立っているレジスタへ(またはNaTVal)アクセスしても、例外は発生しない。 このような命令の実行結果は、NaT または NaTVal となる。 汎用レジスタまたは浮動小数点レジスタ以外のシステムの状態を変更するような投機的実行不可の命令で、NaT ビットのたったレジスタの値を利用しようとすると、その場で例外が発生する。 例えば、メモリへのストアなどが該当する。
ia64 には、CPU レベルでポインタのエイリアシングを解決するための仕掛けがある。 ld.a は、「メモリからデータを読んで成功したことを覚えていろ」という命令である。 もし、ld.a を実行した後に同じアドレスに対してメモリの変更が行われると、読み込み成功リスト=Advanced Load Address Table(ALAT)から除かれ、つまりレジスタの内容がメモリの反映でないとされる。
ポインタのエイリアシングは、ごく一部の例外を除き、コンパイル時に検出することが出来ない。 そのため、これまでコンパイラはポインタの指す先のデータが他のポインタ経由で変更されるかもしれないという前提でしかコードを組み立てることが出来なかった。 アドバンスト・ロードの仕組みを使えば、 ポインタのエイリアシングによるメモリの変更を CPU がトラッキングしてくれるため、コンパイラにとっては目一杯のオプティマイズをかませることができるようになるのだろ う。
さて、後で実際にレジスタの内容を使う前に、レジスタの内容が依然有効であるかどうかをチェックし、無効なら再度読み込みを行う。
最もシンプルな形式は、ld.c.nc。 アドバンスト・ロードが依然有効であるかどうかをチェックし、有効ならそのまま。無効になっていたら、再度読み込みなおす。 ld.c.nc の "nc" は、non clear の意で、アドバンスト・ロードのリストにエントリをそのまま残すことを指示する。 リストからエントリを消す(もうそのポインタは使わないよん)のは、ld.c.clr である。
もうちょっと複雑なチェックを行うため、chk.a 命令がある。chk.a には、レジスタとジャンプ先を指定出来る。 アドバンスト・ロードが無効になっていたら、ジャンプ先へ飛び、計算をやり直すことが出来る。 多分こんな感じになるのだろう。
ld.a r32 = [r38] ;; dep r33 = r32, r34, 8, 4 ... chk.a.clr r32, failed continue: ... failed: ld r32 = [r38] ;; dep r33 = r32, r34, 8, 4 br continue
投機的メモリ読み込みとアドバンスト・ロードを組み合わせた、ld.sa なんかもある。
|
none |
普通のロード |
|
|
s |
Speculative load |
例外は遅延され、NaTビットがセットされる。
|
|
a |
アドバンスト・ロード |
エントリがALATに追加され、ウォッチの対象になる。 アクセスするアドレスが non-speculative の属性を持っていれば、ターゲットレジスタとNaTビットはクリアされて、ALATにはエントリが追加されない。
|
|
sa |
Speculative advanced load |
エントリがALATに追加され、例外は遅延される。
|
|
c.nc |
Check load - no clear |
ALAT エントリがサーチされる。
見つかれば、再度の読み込みは行われず、ターゲットレジスタの内容は変化しない。
ALATのヒットに依らず、指定されていればベースレジスタの更新は行われる(ポストインクリメントのことかな)。
|
|
c.clr |
Check load - clear |
ALAT エントリがサーチされる。 見つかればエントリは削除され、再度の読み込みは行われず、ターゲットレジスタの内容は変化しない。
|
|
c.clr.acq |
Ordered check load - clear |
c.clr と似ているが、"acquire" セマンティクスで実行される。
|
|
acq |
Ordered load |
|
|
bias |
Biased load |
実装に、キャッシュラインの排他的所有権のヒントを与える |
なお、ALATのサイズには限りがある(実装依存)ので、実際にはメモリの内容が変化していなくても、ld.c で再度の読み込みが行われることがある。
ia64の命令実行は、一般にアウトオブオーダで行われるが、命令のリタイア順序を確定する必要のあるケースが存在する。 また、同じメモリ位置に対して、read-after-write (RAW), write-after-write (WAW), write-after-read (WAR) のデータ依存が生じる場合、メモリアクセスの順序が保たれなければならない。
たとえば、メモリ・マップド・I/O のためというのがひとつ。 それから、マルチプロセッサでプロセッサ間のコヒーレンシを保つために必要なことがある。
メモリアクセスのオーダリングは、次の4種類。
初期のia64のコードでは、これらはあまり見ないんじゃないかな。
メモリアクセスには、一時的なローカリティと、非一時的なローカリティがある。 実装依存で、ローカリティに対するヒントを与えることが出来る(データアクセスのみ)。
これらのキャッシュコントロールの実装は、実装依存である。 実装がサポートしていなくても、プログラムの実行結果そのものに変わりはない。 というわけで、今はこれ以上の詳細には立ち入らない。
その他キャッシュコントロールとして、fc という、キャッシュをフラッシュする命令がある。
プレディケイト・レジスタと組み合わせて、条件ジャンプ/コールが出来る。 分岐先プリフェッチの指定が出来る(が、ディスアセンブルを読むだけならあまり気にしなくて良さそう)。
ブランチ先は、常にバンドル単位。 つまり、スロット0がジャンプ先になる。
ブランチには、IP相対ブランチと、インダイレクトブランチの2種類がある。 IP相対ブランチは、符号付21ビットのディスプレースメントをもち、現在のバンドルを指すIPに加算される。 IP相対で±16MBの、バンドル・アラインなアドレスへジャンプ出来る。
インダイレクトジャンプは、ブランチレジスタの指すアドレスへジャンプする。
条件ジャンプ/コールは、プレディケイト・レジスタの指定で可能になる。
|
br.cond |
コンディショナル or アンコンディショナル ブランチ
|
|
br.call |
コンディショナル or アンコンディショナル コール
|
|
br.ret |
関数からのリターン
|
|
br.cloop |
カウンテッド・ループ。
ar レジスタは、特殊レジスタの一種で、アプリケーション・レジスタ。 IP相対アドレスのみ。アンコンディショナル。 プレディケイト・レジスタで修飾できない。
|
|
ctop, cexit |
モジュロ・スケジュールド・カウンテッド・ループ
|
|
wtop, wexit |
モジュロ・スケジュールド・while・ループ
|
ar.lc レジスタが0でなければ、ar.lc をデクリメントして、オペランドへジャンプ。
対象となるレジスタは、ar.lc は固定されている。
なんでそういうことするかな〜。
まきっと、レジスタを固定することによってパフォーマンスが向上するんでしょう。
Cで擬似的に書くと、次のようになる。
if (ar.lc) {
--ar.lc;
goto IP + target25
}
たとえば、QWORDを4つコピーする場合には、こんなコードになるんでしょう。 ar.lc の初期値が3なのに注意。
mov ar.lc = 3
loop:
ld8 r29 = [r32], 8;; // 読み込んで、オートインクリメント
st8 [r33] = r29, 8;; // 書き込んで、オートインクリメント
br.cloop loop
|
spnt |
Static Not-Taken |
このブランチを無視して、予測のためのリソースをアロケートするな
|
|
sptk |
Static Taken |
常に予測が当たるとし、予測のためのリソースをアロケートするな
|
|
dpnt |
Dynamic Not-Taken |
ダイナミック予測のハードウェアを使え。 もしダイナミック履歴情報が存在しなければ、ブランチを無視しろ
|
|
dptk |
Dynamic Taken |
ダイナミック予測のハードウェアを使え。 もしダイナミック履歴情報が存在しなければ、予測が当たるとしろ |
|
few or none |
Few lines |
ジャンプ先のアドレスを少しだけ(実装依存)プリフェッチしろ
|
|
many |
Many lines |
ジャンプ先のアドレスをたくさん(実装依存)プリフェッチしろ |
|
none |
Don't deallocate
|
|
clr |
Deallocate branch information |
モジュール間のコールは、ブランチ・レジスタを使った間接ジャンプになる。
gpレジスタ は、関数が呼ばれた時点で正しく初期化されていることになっているので、呼び出し側が呼び出し先のモジュールのグローバルデータテーブルに合わせてセットしなくてはならない。
alloc r33=0, 3, 2, 0 mov r32=b0 // リターンアドレスを保存 addl r31=@gprel(__imp_KeEnterCriticalRegion#),gp // テーブルのアドレスをr31に mov r34=gp;; // gpを保存 adds sp=-16, sp // nop.i 0;; ld8 r30=[r31] // 呼び出し先モジュール内のデスクリプタのアドレス ld8.nta r3=[sp] // ?? nop.b 0;; ld8 r29=[r30], 8;; // 呼び出し先関数のアドレス ld8 gp=[r30] // 呼び出し先モジュールのgpをセット mov b6=r29 // b6にアドレスをセット nop.m 0 nop.f 0 br.call.sptk.few b0=b6;; // 呼び出し mov gp=r34 // 呼び出し元のgpを復元
|
システム環境 |
アプリケーション環境 |
使用法
|
|
ia32 |
ia32インストラクションセット |
ia32プロテクテッド・モード、リアル・モード及び仮想8086モードの、アプリケーションとOS。 ia32 Pentium, Pentium Pro, Pentium II, Pentium IIIプロセッサと互換。
|
|
ia64 |
ia32 プロテクテッド・モード |
ia64システム環境下での、ia32 プロテクテッド・モードアプリケーション (OSがサポートしていれば)。 |
| ia32リアル・モード |
ia64システム環境下での、ia32リアルモードアプリケーション(OSがサポートしていれば)。 | |
| ia32仮想モード |
ia-32仮想86モード(OSがサポートしていれば)。 | |
| ia64インストラクション・セット |
ia64システム環境下での、ia64アプリケーション。 |
ia64 が大いに参考にしたという、PA-RISC…
[ PA-RISC References ]
void cat(const TCHAR* fname = NULL)
{
static bool is1st = true;
if (is1st) {
is1st = false;
if (options & NO_BUFFERED_OUTPUT) {
// non buffered mode
if (setvbuf(stdout, NULL, _IONBF, 0))
perror("setvbuf");
}
else {
if (setvbuf(stdout, NULL, _IOFBF, LARGE_BUFSIZE))
perror("setvbuf");
}
}
complex_cat(fname);
}
// Function compile flags: /Ogs
.section ??.?cat@@YAXPEBG@Z = "axD", "comdat"
.secalias ??.?cat@@YAXPEBG@Z, ".text"
.align 16
// Begin code for function: ?cat@@YAXPEBG@Z:
.proc ?cat@@YAXPEBG@Z#
.align 32
?cat@@YAXPEBG@Z: // COMDAT
$L21839:
// 282 : {
// 283 : static bool is1st = true;
// 284 : if (is1st) {
// 285 : is1st = false;
// 286 : if (options & NO_BUFFERED_OUTPUT) {
// 287 : // non buffered mode
// 288 : if (setvbuf(stdout, NULL, _IONBF, 0))
// 289 : perror("setvbuf");
// 290 : }
// 291 : else {
// 292 : if (setvbuf(stdout, NULL, _IOFBF, LARGE_BUFSIZE))
// 293 : perror("setvbuf");
// 294 : }
// 295 : }
// 296 :
// 297 : complex_cat(fname);
// 298 : }
ポポローグ
{ .mii //R-Addr: 0X00
レジスタスタックのアロケート
alloc r34=1, 3, 4, 0 //282 cc:0
リターンアドレスの退避
mov r33=b0 //298 cc:0
スタティック変数is1stのアドレスを取得
addl r29=@gprel(?is1st@?1??cat@@YAXPEBG@Z@4_NA#),gp //284. cc:0
} // 00000 90 00 08 03 a0 00 62 00 02 10 05 80 08 21 10 00
{ .mmi //R-Addr: 0X010
グローバル変数のアドレスを取得
addl r30=@gprel(?options@@3KA#),gp;; //286.R cc:0
addl r31=@gprel(__imp__iob#),gp //292.R cc:1
setvbufのスロットのアドレスへのポインタを取得
addl r28=@gprel(__imp_setvbuf#),gp //292.Rm cc:1
} // 00010 90 00 08 03 80 48 00 04 01 f0 24 00 02 00 f0 0a
{ .mii //R-Addr: 0X020
自分のgpを退避
mov r35=gp //298 cc:1
引数に0を積んでおく
mov r38=0;; //292.R cc:1
mov r37=0 //292.R cc:2
} // 00020 90 00 00 04 a0 48 00 00 02 60 21 00 02 01 18 02
{ .mmi //R-Addr: 0X030
スタティック変数is1stにアクセス
ld1 r27=[r29];; //284. cc:2
0と比較して、結果をp14とp15に保存
cmp4.eq p14,p15=r0, r27 //284. cc:3
nop.i 0
} // 00030 00 04 00 00 00 71 1e 6c 00 e0 10 00 3a 00 d8 0a
{ .mfb //R-Addr: 0X040
nop.m 0
nop.f 0
スタティック変数is1stがfalseなら分岐
(p14) br.cond.dptk.few $L21579#;; //284. cc:3
// taken 74952015, not-taken 25047985
} // 00040 42 00 01 40 07 00 02 00 00 00 00 01 00 00 00 1d
{ .mii //R-Addr: 0X050
グローバル変数optionsをr25へ代入
ld4 r25=[r30] //286. cc:4
_iobへのポインタへのポインタを取得
addl r21=@gprel(__imp__iob#),gp //288.R cc:4
4つ目の引数として、512を積んでおく
mov r39=512 //292.R cc:4, 00000200H
} // 00050 90 10 00 04 e0 48 00 04 01 50 10 10 3c 00 c8 00
{ .mmi //R-Addr: 0X060
setvbufのスロットのアドレスを取得
ld8 r22=[r28];; //292.R cc:4
ld8 r26=[r31] //292.R cc:5
グローバル変数optionsのNO_BUFFERED_OUTPUTビットがゼロかどうか調べる
tbit.z p14,p15=r25, 4 //286. cc:5
} // 00060 50 3c c8 81 c0 20 30 7c 01 a0 10 18 38 00 b0 0a
{ .mfb //R-Addr: 0X070
is1stに0を代入
st1 [r29]=r0 //285. cc:5
nop.f 0
optionsのNO_BUFFERED_OUTPUTビットがゼロなら分岐
(p14) br.cond.dpnt.many $L21576#;; //286. cc:5
// taken 50000000, not-taken 50000000
} // 00070 43 00 00 a8 07 00 02 00 00 00 11 80 3a 00 00 1d
{ .mii //R-Addr: 0X080
_iobのアドレスを取得
ld8 r27=[r21] //288. cc:6
mov r20=r22 //288. cc:6
_IONBFを引数レジスタに積む
mov r38=4 //288. cc:6
} // 00080 90 00 00 44 c0 42 00 58 01 40 10 18 2a 00 d8 00
{ .mmi //R-Addr: 0X090
NULLを引数レジスタに積む
mov r39=0;; //288. cc:6
stdoutのアドレスを計算、引数レジスタに積む
adds r36=48, r27 //288. cc:7, 00000030H
nop.i 0;;
} // 00090 00 04 00 00 00 42 00 6d 82 40 24 00 00 01 38 0b
{ .mmi //R-Addr: 0X0a0
setvbufのアドレスを取得
ld8 r19=[r20], 8;; //288. cc:8
setvbufのあるDLLのgpを取得
ld8 gp=[r20] //288. cc:9
setvbufのアドレスをb7へ
mov b7=r19 //288. cc:9
} // 000a0 07 00 09 30 e0 20 30 50 00 10 14 18 28 20 98 0a
{ .mfb //R-Addr: 0X0b0
nop.m 0
nop.f 0
setvbufを呼び出す
br.call.sptk.few b0=b7;; //288. cc:9
} // 000b0 12 80 00 78 00 00 02 00 00 00 00 01 00 00 00 1d
{ .mib //R-Addr: 0X0c0
mov gp=r35 //288. cc:20
cmp4.eq p14,p15=r0, r8 //288. cc:20
(p14) br.cond.dpnt.few $L21579#;; //288. cc:20
// taken 42067089, not-taken 57932911
} // 000c0 43 00 00 c0 07 71 1e 20 00 e0 21 00 46 00 08 11
{ .mib //R-Addr: 0X0d0
addl r31=@gprel(__imp_perror#),gp //289. cc:21
addl r36=@gprel(??_C@_07HHBPNGAN@setvbuf?$AA@#),gp //289. cc:21
nop.b 0;;
} // 000d0 20 00 00 00 00 48 00 04 02 40 24 00 02 00 f8 11
{ .mmi //R-Addr: 0X0e0
ld8 r30=[r31];; //289. cc:22
ld8 r29=[r30], 8 //289. cc:24
nop.i 0;;
} // 000e0 00 04 00 00 00 28 30 78 41 d0 10 18 3e 00 f0 0b
{ .mib //R-Addr: 0X0f0
ld8 gp=[r30] //289. cc:25
mov b7=r29 //289. cc:25
br.call.sptk.few b0=b7;; //289. cc:25
} // 000f0 12 80 00 78 00 03 80 04 e8 70 10 18 3c 00 08 11
{ .mfb //R-Addr: 0X0100
mov gp=r35 //289. cc:0
nop.f 0
br.cond.sptk.few $L21579#;; //291. cc:0
} // 00100 40 00 00 80 00 00 02 00 00 00 21 00 46 00 08 1d
$L21576:
{ .mii //R-Addr: 0X0110
ld8 r20=[r22], 8 //292. cc:0
adds r36=48, r26;; //292. cc:0, 00000030H
mov b7=r20 //292. cc:1
} // 00110 07 00 09 40 e0 42 00 69 82 40 14 18 2c 20 a0 02
{ .mfb //R-Addr: 0X0120
ld8 gp=[r22] //292. cc:1
nop.f 0
br.call.sptk.few b0=b7;; //292. cc:1
} // 00120 12 80 00 78 00 00 02 00 00 00 10 18 2c 00 08 1d
{ .mib //R-Addr: 0X0130
mov gp=r35 //292. cc:12
cmp4.eq p14,p15=r0, r8 //292. cc:12
(p14) br.cond.dpnt.few $L21579#;; //292. cc:12
// taken 42067089, not-taken 57932911
} // 00130 43 00 00 50 07 71 1e 20 00 e0 21 00 46 00 08 11
{ .mib //R-Addr: 0X0140
addl r31=@gprel(__imp_perror#),gp //293. cc:13
addl r36=@gprel(??_C@_07HHBPNGAN@setvbuf?$AA@#),gp //293. cc:13
nop.b 0;;
} // 00140 20 00 00 00 00 48 00 04 02 40 24 00 02 00 f8 11
{ .mmi //R-Addr: 0X0150
ld8 r30=[r31];; //293. cc:14
ld8 r29=[r30], 8 //293. cc:16
nop.i 0;;
} // 00150 00 04 00 00 00 28 30 78 41 d0 10 18 3e 00 f0 0b
{ .mib //R-Addr: 0X0160
ld8 gp=[r30] //293. cc:17
mov b7=r29 //293. cc:17
br.call.sptk.few b0=b7;; //293. cc:17
} // 00160 12 80 00 78 00 03 80 04 e8 70 10 18 3c 00 08 11
{ .mfb //R-Addr: 0X0170
mov gp=r35 //293. cc:28
nop.f 0
nop.b 0;;
} // 00170 20 00 00 00 00 00 02 00 00 00 21 00 46 00 08 1d
$L21579:
// 298 : }
{ .mfb //R-Addr: 0X0180
mov r36=r32 //297. cc:0
nop.f 0
br.call.sptk.few b0=?complex_cat@@YAXPEBG@Z#;; //297. cc:0
} // 00180 50 00 00 08 00 00 02 00 00 00 21 00 40 01 20 1d
{ .mii //R-Addr: 0X0190
nop.m 0
mov.ret b0=r33;; //298 cc:11
mov.i ar.pfs=r34 //298 cc:12
} // 00190 00 aa 02 20 00 03 80 05 08 00 00 01 00 00 00 02
{ .mfb //R-Addr: 0X01a0
nop.m 0
nop.f 0
br.ret.sptk.few b0;; //298 cc:12
} // 001a0 00 84 00 08 80 00 02 00 00 00 00 01 00 00 00 1d
// End code for function:
.endp ?cat@@YAXPEBG@Z#
void swab(int& c)
{
c = ((c & 0xff00) >> 8) | ((unsigned char)c << 8);
}
.type ?swab@@YAXAEAH@Z# ,@function
.global ?swab@@YAXAEAH@Z# // swab
// Function compile flags: /Ogs
.section ??.?swab@@YAXAEAH@Z = "axY", "comdat"
.secalias ??.?swab@@YAXAEAH@Z, ".text"
.align 16
// Begin code for function: ?swab@@YAXAEAH@Z:
.proc ?swab@@YAXAEAH@Z#
.align 32
?swab@@YAXAEAH@Z: // COMDAT
// 125 : c = ((c & 0xff00) >> 8) | ((unsigned char)c << 8);
// 126 : }
{ .mii //R-Addr: 0X00
ld4 r31=[r32] //125. cc:0
mov r28=255;; //125. cc:0, 000000ffH
extr r29=r31, 8, 24 //125. cc:1
} // 00000 52 5c f9 13 a0 48 02 03 f9 c0 10 10 40 00 f8 02
{ .mii //R-Addr: 0X010
nop.m 0
zxt1 r30=r31;; //125. cc:1
shl r27=r30, 8 //125. cc:2
} // 00010 53 dd b9 e3 60 00 20 7c 01 e0 00 01 00 00 00 02
{ .mmi //R-Addr: 0X020
and r26=r28, r29;; //125. cc:2
or r25=r27, r26 //125. cc:3
nop.i 0;;
} // 00020 00 04 00 00 00 40 1c 68 d9 90 20 0c 3a 70 d0 0b
{ .mfb //R-Addr: 0X030
st4 [r32]=r25 //125. cc:4
nop.f 0
br.ret.sptk.few b0;; //126 cc:4
} // 00030 00 84 00 08 80 00 02 00 00 00 11 90 40 64 00 1d
// End code for function:
.endp ?swab@@YAXAEAH@Z#
dbi0 = 0 dbi1 = 0
dbi2 = 0 dbi3 = 0
dbi4 = 0 dbi5 = 0
dbi6 = e000000000000000 dbi7 = e0000165dfd54760
dbd0 = 0 dbd1 = 0
dbd2 = 0 dbd3 = 0
dbd4 = e000000086e6c3e0 dbd5 = 0
dbd6 = e0000165dfe2fd40 dbd7 = 0
gp = 78190000 0 r2 = e0000165dcf1f5c0 0
r3 = 0 0 r4 = 6fbffe8fbd0 0
r5 = 6fbffe8f160 0 r6 = 6fbfffde000 0
r7 = 78190000 0 r8 = c0000258 0
r9 = 77eb5c00 0 r10 = aa01 0
r11 = 10082a2018 0 sp = 6fbffe8fc80 0
r13 = 6fbfffdc000 0 r14 = 0 0
r15 = 6fbffe8fc80 0 r16 = e0000165dcf1f6b0 0
r17 = e0000000ffff0b30 0 r18 = e0000165dcf1f808 0
r19 = e0000165dcf1f7f0 0 r20 = 4020 0
r21 = e000000086f099a0 0 r22 = e000000086ec0060 0
r23 = 9804c8a70033f 0 r24 = 7f05 0
r25 = 0 0 r26 = 0 0
r27 = f 0 r28 = 6fbffe8f1a0 0
r29 = 6fbffe8f190 0 r30 = 6fbffe8f188 0
r31 = 6fbffe8f18c 0 intnats = 0
preds = aa41
b0 = 77ed21e0 b1 = 0
b2 = 0 b3 = 0
b4 = 0 b5 = 0
b6 = e000000083084830 b7 = e000000083068630
unat = 0 lc = 0
ec = 0 ccv = e0000165dcf1f590
dcr = 7f05 pfs = c000000000000184
bsp = 6fbffe90280 bspstore = 6fbffe90280
rsc = f rnat = 0
ipsr = 1013082a6018 iip = 77ed21e0
ifs = 8000000000000184 fcr = 40
eflag = 202 csd = cfbfffff00000000
ssd = cf3fffff00000000 cflag = 60100000111
fsr = 0 fir = 0
fdr = 0
r32 = c0000258 0 r33 = 77eb5c20 0
r34 = c000000000000003 0 r35 = c0000258 0
To be continued...
ホーム ざれごと ワシントン州 ツール NT豆知識 Win32プログラミングノート 私的用語 ジョーク いろいろ ゲーム雑記 Favorites 掲示板 Mail