一つ上へ
ホーム ざれごと ワシントン州 ツール NT豆知識 Win32プログラミングノート 私的用語 ジョーク いろいろ ゲーム雑記 Favorites 掲示板 Mail
VC++のセットアップで、Unicodeアプリケーション作成に必要なライブラリをインストールします。
プロジェクトを作成またはオープンし、 ビルドメニュー→設定で、プロジェクト設定ダイアログを出します。
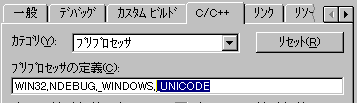
C/C++タブからプリプロセッサを選び、_MBCSのdefineを削除、代わりに_UNICODEのdefineを追加します。
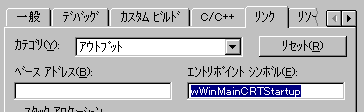
さらにリンクのアウトプット設定で、エントリポイントシンボルを wWinMainCRTStartupに変更します。
オプションダイアログで指定する代わりに、リンカへの指示をソースコードに埋め込むこともできます。 次の pragma を、ソースコードのどこか (your_app.cppが適当かと) に書いておけばおっけーです。
#if defined(UNICODE) || defined(_UNICODE) #pragma comment(linker, "/entry:\"wWinMainCRTStartup\"") #endif
MultiByteToWideChar()とWideCharToMultiByte() APIを使います。
ANSI文字列は、1文字につき最大Unicode1文字を占めます。 DBCS文字の場合には、2文字につきUnicode1文字を占めます。 Unicodeの1文字は、最大2バイトのANSI文字に変換されます。
したがって、バッファサイズに関しては、以下の原則があります。
追記: ここでの議論は、サロゲートを考慮していません。 正しくサロゲートを扱うためにはおおざっぱな計算によらず、やはり API に頼らざるを得ません。
Win32/VC++では、Unicode/MBCSどちらでコンパイルしても、正しい関数を呼び出すためのマクロが用意されています。
例えば、文字列のコピーには通常 strcpy() を使いますが、これに対応するVC++のマクロは _tcscpy() です。 これは、tchar.hで次のように定義されています。
#ifdef _UNICODE #define _tcscpy wcscpy #else #define _tcscpy strcpy #endif
この他に用意されているマクロを、!UNICODEの場合の定義とともに挙げておきます。
![]()
ホーム ざれごと ワシントン州 ツール NT豆知識 Win32プログラミングノート 私的用語 ジョーク いろいろ ゲーム雑記 Favorites 掲示板 Mail