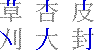
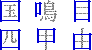
| 11.24 17:30 あれ、また同じ時間だ。どうなってんだ……(笑)。 そういえばNetscapeがAOLに買収されるんだそうな。朝日新聞で見たんだったかな? まあニュアンス的には合併に近いみたいなのでまあいいんだけど。40億ドルってのが高いのか安いのかはさっぱりわからないけど、やっぱりすごいことだよなぁ。 Geneva2OsakaでFinderが不安定になったりTEで選択するとフリーズするというような報告を受けているのでこれを書き終わったらちょっとチェックの予定。とりあえずこの手のバグが出る方はb9を使うのをすすめる。おそらく今までの中で一番バグの少ない安定したバージョンだと思われる。0.80でももちろんいいけど。 で、待ちに待った(え? 待ってない?(汗))四角号碼(しかくごうま)の話。うちにある漢和辞典(漢語林)には索引の一つに四角号碼索引というものがあって、ルールを覚えさえすればほかのどんな引きかたよりも早く引ける(たぶん)。漢字をその漢字の形に基づく4桁のコードで分類し、そのコードでひく。だいたい多くても同じコードに属するものは20個程度だし(付角を含めて5桁にすればもっと減るが)、形だけで判断するから読みも部首も分からなくても大丈夫というところに大きな特徴がある。 ここでルールの話をするのが適当かどうかちょっと悩んだのだが、その話をしないと全く書くことがなくなってしまいそうなので一応ざっと書いてみようと思う。そのうちこれを使った漢字変換用の辞書をリリースするつもりなので(辞書自体はできているのだけど(JIS第2水準のみだが)ドキュメントがまだなので……)ここで書いておいても構わないだろうと。 「四角」とついていることからもわかるかもしれないけど、このコードは、漢字の4つの角の筆形をコード化し、それを順番に並べて表記する。その順番は左上、右上、左下、右下の順番になる。これを間違えるとどうがんばってもみつからないので注意(笑)。それから実際のコード化だが、これがちょっとややこしい。基本は覚えるだけなのだが「あれ? これはどっちだろう」なんて疑問に思うことが時々ある。ここではそういう疑問に答えるところまでは考えず、とりあえず基本ルールだけ書くことにする。
まずはこれだけのルールを覚える。それから前提として、0ってのは3ととれなくはないがこれは0とするし、9についても23ととれなくもないがこれは9とする。要は単筆より複筆を優先するというわけ。ってまあそうじゃなかったら複筆が存在する意味がなくなってしまうから、ね(笑)。 で、実際の例をあげると、漢語林では「行」という漢字を例としてあげているが、まず左上の「ノ」をとってこれが「2」、右上の「一」をとってこれが「1」、左下は縦の棒だから「2」、右下も同様に「2」で、「2122」というコードになる。「端」では「0212」だし、「深」は「3719」(註 これまで3729と書いていたが、3719の間違い。030512修正)、「裁」は「4375」となる。衣の7はちょっとややこしいかな。 ここで、欠番についてちょっと説明。例えば「木」とか、「4090」になるんだけどこの場合の「0」はさっきの表の「0」ではなくて、「あ、もうさっき使っちゃったから残ってないや」って意味の欠番の「0」になる。最初左上で交差している縦線を使ってしまうと、右上の時にはもう残っていない。また、左下で下の3つの画を使ってしまうと右下は残らない……というわけ。同様に「宣」では「3010」になるし「直」は「4071」などというふうになる。「持」とかだと右下が欠番で、「5404」になる。 で、さらに……、口、門、行の構えで構成されている字は、まわりだけとっていると構えの説明だけで終わってしまうので(要するに漢字の特定ができにくい)、左下、右下は構えを無視した状態で考える。「因」なら下は「大」で判断して「6043」になるし、「閉」なら「才」で判断して「7724」という具合だ。さっきの説明でもあったけど構えだけのパターンでは、「行」は「2122」だし、「門」は「7777」(7722ではないのね……ぐはぁ(笑))という風になる。それから「菌」みたいに上になんかついているやつは素直に「4460」とする。 とりあえずこんなもんで。付角は省略(笑)。その他細かいルールも省略(笑)。細かいことが知りたい人はそれ相応の辞書なりを参照のこと。また、ここで書いたルールは「広漢和辞典」の方式なんだそうで「新華字典」などで採用されているいわゆる「新方式」とは異なっているとのこと。だからまあぼくがそのうち公開するかも知れない辞書は新方式ではないってことね。 ふー、疲れた。んじゃ、最後に「集」はいくつかな? と言い残して終わり。 19:45 考えたら2回以上書いても同じ日なんだから今後は時間だけ書くことにしよう。 ルータの設定の件の続き。結局は自動接続はオンに戻して切断も勝手にさせるのに任せることに決定(笑)。どのくらいの時間で切られるのかよく知らないけど(Telnetじゃないとみれないのかなー)気付いたらきれてるし(笑)。で、自動接続オフだとそこからまた接続詞にいかないといけなくてこれがとてつもなくだるい(笑)。 とりあえずそういうことにしてしまったらかなり気持ちよくなった。電話代はこわいけどそれを除けば専用線環境に近いし(笑)。 Geneva2Osaka 1.00b12をリリース。とりあえず68k環境でSimpleTextなどTEを使用したアプリケーションを使用した時に適当な長さの(「あ」を40文字でも再現(苦笑))テキストを入力してすべてを選択するとフリーズあるいはタイプ1のエラーが起こるバグの修正。どうも文字数は関係なく途中で行が折り返されているかどうかが関係しているみたいだけど、そのときにTextWidthにとんでもないバイト数の文字列の長さをチェックしろという要求がくるようなのだ。そこでテキスト変換用のバッファを確保しようとしてエラーが起こっていた。暫定的に、バッファが確保できない時は変換しないという方法で対処。普通の要求であれば足りるだろうということでこういう仕様に変更。本来ならばメモリが足らなければテンポラリメモリを使ってなんとかするべきかもしれないが、そこまでして半角カナを直すまでもないだろうということで。 しかし、ppc環境では同じことをしても何も問題がないことから、おそらくそのとんでもないバイト数の……という要求がきていないのではないかと思う(未確認だが)。そうすると68kのToolboxのバグなのかも知れないと思ったりもするが実際のところはどんなもんかな?? バグ情報に書いてほしいことのリストをドキュメントに追加したが、それよりも前に作ったメールを送るスタックを使った方がおもしろかったかもしれない(笑)。あ、でもICを使っていない人はだめだからちょっといまいちかな? うーむ。。 |
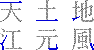
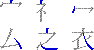
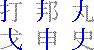
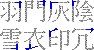

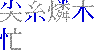
|
← to November 23, 1998 ↑ to November index → to November 25, 1998 |