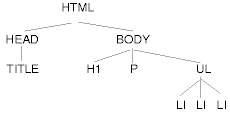
マークアップとは,謂はば “文書構造の木” となる文書ツリー(document tree)を構築する行爲です。
HTMLでは文書ツリーを構成する單位のことを要素(element)と呼びます。HTML文書は,一つのhtml要素から枝分かれした要素の階層構造として,ツリーを形成します。html要素の中身は,head要素-body要素を順に一箇づつ含みます。(參照:後述例)
さらにhead要素には文書に關する情報を示す要素を含み,body要素には本文としての役割を持つ要素を含みます。本文の構造要素には,見出し(h1〜h6),問ひ合せ先(address),パラグラフ(p),引用(blockquote),リスト(ul,ol,dl)などがあります。
文書ツリーのそれ自身はプレゼンテーション構造を持たないため(ある程度の表現が「期待」されるにしても),それだけでは實體として表現できません。實際にツリーを目に見えるやうに,聞こえるやうに,觸れられるやうにするには,一つ以上のスタイルシートが必要になります。ただしHTML適合ブラウザであれば,豫め少くとも一つのスタイルシートを内藏してゐるので,かならず人間が知覺できる表現で情報が傳へられます。
すなはち著者がスタイルシートを用意しなくとも,環境に應じた表現方法でHTML文書は樣々にレンダリングされます。このとき著者は,自身の制作環境における文書のレンダリング結果が,UAに内藏されたデフォルトスタイルの働きに過ぎない點に,注意すべきです。
著者が自身のHTML文書についてプレゼンテーションを施すさいには,CSSスタイルシートの仕組を用ゐるべきです。
HTML文書で使用できる要素の規則は,文書型定義(DTD)の中にある要素型(element type)宣言で定められてゐます。嚴密型DTDの要素型であれば文書構造として必要最小限のセットで構成されるので,覺えるべき數はそれ程多くはありません。
文書内に潛在する暗示的な要素について,それらを凡ゆるUser Agentが理解できるやう顯在化するには,DTDに基いて,その要素をタグと呼ばれる目印を用ゐて明示する必要があります。この要素を明示する行爲をマークアップ(マーク附け)と呼びます。
要素のマークアップは,一般に次の三部分から構成されてゐます; すなはち "開始タグ","内容(content)","終了タグ" です。 要素型の名稱については,開始タグ(<要素型名>のやうに書く)として,または終了タグ(</要素型名>のやうに書く)として現れます。
たとへば一つの段落(Paragraph)を意味するp要素といふ要素なら,次のやうにマークアップされます:
<p>パラグラフとは,一つの主題を持つた一つ以上の文の集まりのことで……</p>各要素の内容には要素型宣言の "内容モデル" に隨つて,文字データや下位要素が含まれ得ます:
<p><dfn>パラグラフ</dfn>とは,一つの<em>主題</em>を持つた一つ以上の……</p>この例では,p要素の下位要素としてdfn要素とem要素を包含してをり,"入れ子の構造" を成してゐます。このやうにマークアップは,ツリーの「枝分かれ」が破綻しないやう行はねばなりません。多數の要素範圍が "互ひ違ひ" になる樣なマークアップは不正です。
HTML 4では要素型名の大文字と小文字は區別されません。XHTMLでは常に小文字で記述します。
HTML 4仕樣においては “タグの省略” を許容する場合もあります。これはDTDで規定されてをり,文脈上その存在や範圍が自明な場合に限られます。たとへばp,li,dt,dd要素は終了タグを省略可能です。また開始タグすら省略可能な場合もあります。
たとへばp要素は自身も含め,あらゆるブロックレヴェル要素を包含できません。つまり,次のブロックレヴェル要素が現れた時點で終了します。li要素においても同樣で,兄弟關係の次のli要素が出現した時點,またはul・ol要素の終了タグ直前で終了します。
またhtml,headおよびbody要素などは,ソース文書内のマークアップで明示されてなくとも,User Agentが文書を解析する際には常にその存在が推量されて,文書ツリーの一部に組込まれます。すなはち,これら要素はどの樣な場合でも常に存在します。
しかしUser Agentのなかには,要素の終りを内容モデルの文脈から適切に判斷しないものも存在します。たとひある要素のタグを省略可能であるにしても,マークアップで明示して置いてください。そのはうがソース文書内のマークアップも把握しやすくなります。
なほXML應用のXHTMLでは要素を推量しないので,要素範圍について常に明示せねばなりません。
HTMLの要素型には,内容が存在しない(持てない)ものも在ります。たとへば行區切りの強制であるbr要素は内容を持てません。その役割は行の終りを示すことだけです。HTML 4では,このやうな空(empty)要素は終了タグを絶對に持ち得ません。
ただしXML應用であるXHTMLではたとひ空要素であつても,開始タグと終了タグのペアが必要です。しかし一般にはHTML 4との互換性,もしくは表記の簡略化のために,空要素タグが用ゐられます; <br /> のごとく。これはHTML 4では不正です。
(補足:これらを誤つて空タグ
と呼んではいけません。空タグと言ふとそれはSGMLの短縮タグ機構を意味します。)
タグは決して,命令ではありません。またHTMLは決して,プログラミング言語ではありません。もしその樣な言語であれば,作成者はコンピュータに對して “處理の流れ:手順” を明確に指示せねばならず,處理系は “規定の動作” を實行せねばなりません。
HTMLはマークアップ言語の一種であり,文書内に潛在してゐる要素をタグに據つて明らかにし,その役割をあらゆるUser Agentがユニヴァーサルに理解できる樣にする爲のものです。HTML文書は具體的な表現を強要しません(ある程度「期待」されるにしても)。
HTML文書をレンダリングするUser Agentは,まづソース文書に記されたマークアップを解析し,そして一つのルートから枝分かれした要素の階層構造としてツリーを形成します。この文書ツリーを實際にどう表現するかは,スタイルシートがその役割を擔ひます。文書に適用されるスタイルシートには,三通りの出處があります: その内容の著者が指定したもの,ユーザが指定したもの,UAに備はつてゐるもの(デフォルト)。
HTMLは文書の構成要素をツリーとして表現するだけで,整形構造はスタイルシートの作用によるものです。
次例は,HTML 4.01仕樣に基かれた正當(Valid)なソース文書です:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html>
<title>My home page</title>
<body>
<h1>My home page</h1>
<p>Welcome to my home page!
Let me tell you about my favorite composers:
<ul>
<li>Elvis Costello
<li>Johannes Brahms
<li>Georges Brassens
</ul>
</body>
</html>このソースの場合,文書ツリーは次のやうに解析されます:
HTML4 の文書型定義に則せば,ソース文書内にheadタグが存在しなくとも,文書解析の際にはhead要素の存在が推量されて,文書ツリーの一部に組込まれます。同様に,パーサはp要素やli要素の終了タグがソース文書内に存在しなくとも,それらがどこで終了するのか識別できます。(たとえばp要素は,ブロックレヴェル要素をまったく内包できないので,次のブロックレヴェル要素が出現した時点で終了します)。
ただし,XHTML(およびその他のXML應用言語)で書かれた文書では異つてゐて,要素の推量は行はれません。そして,すべての要素は終了タグを備へてゐる必要があります。すなはちXML應用の文書は常に整形式(well-formed)でなければなりません。
要素には屬性(attribute)といふ關聯特性を含まれ得ます。屬性は自身の名稱と値のペアで構成され,開始タグ内の要素型名の後,終了區切り子 ">" の前に出現します。一つの開始タグには,空白類區切りの多種類の屬性が順不同に出現し得ます。
各屬性には,その要素について「必須(REQUIRED)」のものと,任意の「暗示(IMPLIED)」のものがあります。
次例においては,p要素にclass屬性を設定し,その値として "example" といふ名稱を指定してゐます:
<p class="example">このパラグラフは,class屬性によつて分類されてゐる。</p>屬性値は,デフォルトでは單引用符(':0x27)もしくは二重引用符(":0x22)のどちらかで括るやう,求められます。二重引用符で括られた屬性値には單引用符を含めることができ,この組合せが逆の場合も同樣です。屬性の値として引用符を記すなら,著者は文字參照を用ゐることもできます。たとへば單引用符は ' に據つて,二重引用符は " もしくは " に據つて,表すことができます。
屬性値は引用符で括らなくてもよい場合もあります。それは以下の文字列で構成される場合です: A〜zA〜Z,數字(0〜9),ハイフン(-),ピリオド(.),アンダースコア(_),およびコロン(:)。しかしHTML 4仕樣では,たとひ引用符が省略可能な場合でも,省略しないやう推奬してゐます。省略條件を一々考へながらマークアップするのは面倒ですし,文法エラーを囘避する面からも,常に括つておくのが無難です。
HTML 4では屬性名の大文字と小文字は區別されません。屬性値も同樣に,一般に大文字と小文字を區別しません。ただしXHTML文書においてはDTDで規定される文字通りに屬性/値のペアを示さねばならず,値は常に引用符で括らねばなりません。
HTML 4仕樣では,中核的(core)な屬性としてid,class,title屬性を定義してをり,國際化(i18n)の屬性としてlang,dir屬性を定義してゐます。これらの屬性はHTML 4のほぼすべての要素について,汎用的に使用できるやうに設計されてゐます。
id,class屬性に關してはこの節ではなく,HTML文書の全體構造 - 要素識別子で概説します。
title="text" [CS](補足:[CS]――大文字と小文字を區別することを意味する。)
たとへば,ハイパーリンクの始點アンカー(href屬性を持つa要素)にtitle屬性を設定すると,對象メディアが "視覺系" か "非視覺系" かを問はず,User Agentはユーザに對してリンク先リソースの本質――文書内容に關する短い説明など――を知らせられます。
lang="language-code" [CI]dir="ltr|rtl" [CI](補足:[CI]――大文字と小文字を區別しないことを意味する。)
lang屬性に指定する "言語" とは,自然言語――日本語や英語などのやうに,話したり書いたり身振りなどによつて表現される,人間が意志を傳逹するのに用ゐる言語――を示す,二文字の主コードとそれに連結される副コードから成る言語コードのことです。
lang屬性の目的はUser Agentに對して,與へられた自然言語における一般的な文化慣習に基づいた,より有意なレンダリングを行へるやうにさせようといふものです。lang,dir屬性の詳細は,HTML 4.01仕樣書邦訳 8. 言語情報とテキスト方向を參照のこと。
ウェブのやうにグローバルな情報システムにおいては,ASCIIのやうな小規模な文字集合では十分ではありません。そこでHTML 4仕樣では國際化對應の一環として,文書文字集合に國際符號化文字集合:UCS(ISO/IEC 10646)が採用されてゐます。すなはち,世界中の國や地域など,あらゆるコミュニティで使用されてゐる多樣な(何萬もの)文字を利用できるやうに設計されてゐます。
しかし,あるコミュニティで一般に使用されてゐる文字符號化方法においては,文書文字集合の全ての文字を表現できるとは限りません。また入力環境に依つては文書内に直接記すのが困難な場合もあるでせう。かやうな場合に用ゐるのが文字參照です。
HTMLの文字參照には,次のふたつの形式があります:
UCSベースのUTF-8符號化などを用ゐれば "文字參照" を用ゐずとも,あらゆる文字をぢかに書き記せます。
ただし文書文字集合は,あくまで抽象的な文字情報の集まりです。實際の文字を視覺的に提示するには,使用されてゐる自然言語/用字系ごとに適切なフォントを必要とします。適切なフォントが存在しなければ,UAは "缺落状態" を何らかの方法で知らせるでせう。
(補足:文字參照は,しばしば 特殊文字
として解説されますが,不適切です。前述のとほりHTML 4仕樣では,世界中のあらゆる文字を公平に使用できるやう,設計されてゐます。私たち日本人は,かなや漢字を日常的に讀書きできるので,これらを「特殊」であるとは一般に認識してゐません。しかし,西洋などの文化圈から見れば,當然さうではありません。自分たちの母國語を中心として,他文化の文字を「特殊呼ばゝり」するやうな態度は,傲慢と言へませう。)
數値文字參照は,文書文字集合における當該文字の "符合位置" を指定するためのものです。
數値文字參照には,二通りの形式(10進法もしくは16進法による參照)があります:
&#D; といふ構文。Dは,UCS:ISO/IEC 10646の "10進文字番號D" を意味する。&#xH; といふ構文。Hは,UCS:ISO/IEC 10646の "16進文字番號H" を意味する。以下に數値文字參照(10進法と16進法の兩方)の例を,いくつか提示しておきます:
å | (10進) | ノルウエー語などで使はれる "å" (上にリングが附いた小文字のa)を表現する。 |
å | (16進) | 上述と同じ文字の參照として "å" 表現する。 |
å | (16進) | 上述と同じ文字の參照として "å" 表現する。 |
И | (10進) | キリルの大文字である "И" を表現する。 |
文 | (16進) | 漢字である "文" といふ字を表現する。 |
上述のとほり,數値文字參照の &#x の部分と,それに續く16進數値は大文字と小文字を區別しません。
文字實體參照では,象徴的な名稱により文字を參照します。そのため著者は符號位置の數値を覺える必要がありません。たとへば文字實體參照である å は "å" (上にリングが附いた小文字のa)を參照します。これは å より覺えやすく,直感的です。
HTML 4仕樣では,文書文字集合の全文字について "文字實體參照" を定義する事はありません。たとへば,キリルの大文字である "И" の文字實體參照は存在しません。HTML 4仕樣における文字實體參照は文字実体参照リストを參照してください。
文字實體參照は,大文字と小文字を區別するので注意してください。たとへば Å は,"Å" (上にリングが附いた大文字のA)を參照します。これは先に述べた小文字表記の å が參照する "å" (上にリングが附いた小文字のa)とは異る文字を參照します。
以下に示す四つの文字實體參照は,HTMLの區切り子として解析される文字の囘避として,頻繁に用ゐられます:
< | < (小なり符號)を表現する。 |
> | > (大なり符號)を表現する。 |
& | & (アンパサンド)を表現する。 |
" | " (二重引用符)を表現する。 |
テキスト中に "小なり符號:<" を記したい場合,著者は < を使用して『開始タグの開始區切り子』として誤解析される可能性を囘避すべきです。同樣にテキスト中に "大なり符號:>" を記したい場合,たとひ引用符で括られた屬性値の一部であつたとしても,著者は > を直に記すのではなく,> を使用して,舊式のUser Agentが『タグの終了區切り子』として誤解析してしまふ問題を囘避すべきです。
また著者は,"アンパサンド:&" の代りに & を使用して『文字實體參照の開始區切り子』として誤解析される可能性を囘避すべきです。CDATA型の屬性値には文字參照が出現できるので,著者は屬性値においても & を使用する必要があります。
たとへばURLにはサーヴァに情報を送るために "クエリー" が附加される事があり,そのデータの區切り文字として & は頻繁に用ゐられます。始點アンカー(href屬性を持つa要素)などの參照先としてURLを指定する場合には,& の代りに & を用ゐるべきです。
次に示す始點アンカーは Google™ にデータを送るためのURLを含んでをり,& を文字實體參照に置換へてゐます:
<a href="http://www.google.com/search?num=50&hl=ja&q=HTML">HTMLといふ語を檢索</a>上述でもし & を直に記したとすると,ブラウザは &hl や &q といふ,不明な實體參照として解析するかもしれません。
(補足:しばしば文字實體參照は 特殊文字
扱ひされて,通常では表示できない文字をブラウザ上で表示させる
などと解説されます。しかしながら,文字實體參照で定義されてゐる一部の文字については「JIS X0208:情報交換用漢字符號」にも含まれてゐます。すなはち,一部の文字については日本語環境でも簡單に入力可能であり,和文フォントにグリフも在るので,普通に表示可能です。たとへば "α(アルファ)" を記す場合,文字實體參照を使ふ必然性はありません。そもそも「特殊」だから名前で定められてゐるのではなく,多くのコミュニティで「頻繁」に用ゐられる事例が多いから,覺えやすい直感的な名前で定められてゐるのです。)
HTMLのコメント宣言とは註釈に用ゐるもので,嚴密にはSGMLマーク宣言の中にコメントだけが含まれる状態のことです。
次では,コメント宣言を記述した實際例を提示してゐます:
<!-- これはコメントです -->
<!-- これもまたコメントです。
複數の行に跨る範圍を占めることも可能。 -->コメント宣言を記述する際には,次のやうな決りがあります:
<!" と,コメントの開始區切り子である "--" の間に空白類が在つてはならない。--" と,マーク宣言の終了區切り子である ">" の間には空白類が在つてもよい。次のコメント宣言は,ハイフンが餘計に連續して記されてゐるので,不正になつてゐます:
<!--------- これはコメントです。 --------->ハイフンの代りに等號やほかの記號類を使ふなどして,エラーにならないやうに各自の好みで工夫してください。
コメント宣言の註釈は特別な意味を持たず,文書のレンダリングになんら影響しません。入れ子は不正です。
この宣言もマークアップの一種ですが,要素を明示するタグではありませんし,決して コメントタグ
ではありません。